
[번역]StarCraft2 A New Challenge for Reinforcement Learning 스타크래프트2 강화학습
업데이트:
스타크래프트2 AI 환경설정
원문 : StarCraft2 A New Challenge for Reinforcement Learning
링크 : https://deepmind.com/documents/110/sc2le.pdf

요약
이 논문은 스타크래프트2를 기반으로 하는 강화 학습 환경을 소개한다. 이는 여러 면에서 기존 강화학습에 비해 새롭고 광활한 뿐 아니라, 더욱 도전적이다.
- 다수의 유저가 상호작용하는 멀티-에이전트 문제
- 일부만 관찰된 맵에 의한 불완전한 정보
- 수백 개의 유닛에 대한 선택과 컨트롤을 수반하는 광범위한 행동공간(action space)
- raw input 피쳐 평면으로 인한 넓은 상태공간(state space)
- 수천번의 단계 동안 장기전략(long-term strategies)이 요구되는 신뢰할당(credit assignment) 딜레이 문제.
우리는 스타크래프트2에 대해 관측(observation), 행동(action), 보상(reward)을 설명하고,
게임엔진과 의사소통하는 파이썬 베이스 인터페이스를 오픈소스로 제공한다.
메인 게임 맵 뿐 만 아니라, 우리는 스타크래프트2의 서로 다른 요소에 집중하는 미니 게임을 제공한다.
메인 게임 맵에 대해선, 우리는 실제 고수 유저의 리플레이 데이터셋을 제공한고,
이 데이터를 이용해 신경망을 이용하여 학습시킨 초기 베이스라인이 되는 결과 또한 제공한다.
이는 게임 결과와 유저의 행동 예측에 사용된다.
즉, 스타크래프트2에 적용되는 표준(canonical) 심층강화학습 에이전트로 사용된다는 뜻이다.
미니게임에서의 플레이 목표 수준은 초보 유저와 비교할수 있을 정도이다.
그러므로, 스타크래프트2 강화 학습 환경은 심층강화학습 알고리즘과 아키텍쳐에 대해 새롭운 도전을 제공한다.
1.인트로
최근 발전하고 있는 음성인식, 컴퓨터 비전, 자연어처리는 신경망을 이용해 비선형 점근 함수를 구하기 위한
강력한 툴을 제공함으로써 딥러닝의 부활에 기여했다. 또한 이러한 기술은 아타리 게임, 바둑, 3차원 가상 환경과 로보틱스 분야에서
유의미한 성공을 보이는 강화학습에서도 성공적이라는 것이 입증되었다. 이러한 큰 성공은 어려운 난이도의 분야에서도 시뮬레이션 되었다.
이러한 벤치마크는 진보된 딥러닝과 강화학습 연구결과에 중요한 기여를 하였다.
이는 1차원 이상에서 현재 방법의 역량을 뛰어넘는 도메인의 유효성을 확실히 하는 면에서 대단히 중요하다.
본 논문에서는 새롭고 도전적인 강화학습 도메인인 스타크래프트2라는 게임의 SC2LE(스타크래프트2 학습환경)을 소개한다.
스타크래프트는 실시간 전략 시뮬레이션(RTS) 게임인데, 빠른 micro-action과 높은 수준의 전략수립과 실행능력을 요구한다.
지난 20년 동안, 스타크래프트1과 2는 e-sports의 개척자였으며, 수많은 스타 플레이어를 탄생시켰다.
따라서 최고 수준의 플레이어를 이기는 것은 의미있으며 장기적인 목표가 될 수 있다.
강화학습 관점으로 스타크래프트2는 기존의 한계를 뛰어넘을 만한 최고의 기회를 제공한다.
첫째, 스타크래프트2는 여러 명의 플레이어가 자원을 놓고 경쟁하는 멀티에이전트 문제이다.
또한 각 플레이어들은 공통 목표를 달성하기 위해 수백개의 유닛을 컨트롤 하며 협동하는 lower-level 멀티에이전트라고 볼 수 있다.
둘째, 스타크래프트2는 불완전한 정보 게임이다. 맵은 오직 로컬 카메라를 통해 일부만 관찰가능하며,
플레이어는 정보를 얻기위해 적극적으로 움직여야 한다.
더욱이, 지도에서 정찰하지 않은 곳이 흐리게 표현되는 전장안개(fog-of-war)개념은
적의 상태(state)를 판단하기 위해 플레이어의 적극적인 움직임을 요구한다.
셋째, 활동공간(action space) 는 광활하게 넓으며 그 종류가 다양하다.
플레이어는 대략 $10^8$ 개로 조합된 공간 중 하나의 행동을 선택한다.
그리고 많은 종류의 서로 다른 유닛과 건물 종류가 있는데, 각각은 유니크한 행동으로 이어지며, 여러 종류의 빌드오더가 존재한다.
넷째, 이 게임은 수천개의 프레임과 행동이 지속되고 어떤 유닛을 생산할 것인지 이른 판단(early decision)이 요구되며,
적을 발견하기 전까진 적을 볼 수 없다. 이것은 시간제약적 신뢰할당(temporal credit assignment)과 탐색(exploration)으로 이어진다.
본 논문은 스타크래프트 강화학습을 수월하게 해주는 인터페이스를 소개한다.
- 피여의 낮은 해상도 그리드를 이용해 관측과 행동이 정의 된다.
- 보상(reward)은 스타크래프트2 엔진을 기반으로 컴퓨터 적을 통해 정해진다.
- 간소화된 미니게임 또한 전체 게임맵으로 제공되고 이는 스타크래프트2 전체 게임의 인터페이스로 확장가능하며 관측과 행동이 RGB 픽셀로 드러난다.
- 에이전트는 멀티플레이어 게임에서 마지막 승리 혹은 패배로 순위가 결정된다
- 평가는 실제 사람과 경쟁하기 위해 전체 게임맵으로 제한 된다.
게다가 우리는 실제 사람의 리플레이에 기반한 대량의 데이터셋을 제공하는데 이는 실제 사람이 수백만번 플레이한 것과 같다.
우리는 인터페이스 조합과 이 데이터셋이 기존에 존재하거나 새로운 강화학습 알고리즘을 테스트하기 위한 유용한 벤치마크를 제공할 것이라 믿을뿐만아니라,
퍼셉트론, 메모리와 attention, 순차적 예측(sequence prediction), 불확실성 모델링 등 관점에서 흥미로운 측면이 존재하는데
이는 모두 머신러닝 연구가 활발한 분야이다.
몇몇 환경에서 이미 스타크래프트1 강화학습이 존재한다.
우리 연구는 이전의 환경들과는 다소 다른 측면이 있다.
- 우리는 스타크래프트1이 아닌 스타크래프트2를 이용한다.
- 관측과 행동은 프로그램적이라기 보단, 실제 인간 유저 인터페이스에 기반한다.
- 해당 게임개발사인 블리자드 엔터테인먼트의 서포트를 받는다.
이전 연구 환경에 기반한 현존 최강 스타크래프트 인공지능이라 할지라도 실제 인간 아마추어조차 이길 수 없었다.
이런면에서 보면, 스타크래프트는 흥미로운 게임 플레이 특성과 넓은 유저 기반이 심층 강화학습 연구를 가능하게 한다.
2. 관련 연구
컴퓨터 게임은 인공지능(AI) 연구의 중요한 자원이 될 뿐 만 아니라, 여러 가지 평가, 서로 다른 학습 방법 비교, 표준화된 업무 계획 이슈에 대해 주목할 만한 해결책을 제공한다.또한 또한 여러 가지 장점을 포함하는데,
- 성공이라는 개념이 객관적이고 측정 가능한 점.
- 컴퓨터 게임 특유의 관측 가능한 데이터를 통한 전형적인 아웃풋 흐름.
- 인간이 플레이하기 어려운 난이도는 연구자가 알고리즘을 개발하여 문제를 쉽게 만들어 튜닝하는 것이 아닌 인공지능 그 자체가 가능하도록 한다.
- 게임은 동일한 인터페이스, game dynamics, 실행되도록 디자인되어 있는데 이것은 다른 연구자들과 쉽게 공유 가능하게 한다.
- 흔히 고인물이라 불리는 고수 플레이어가 모여있는 곳이 존재하는데, 이는 높은 기술 수준의 개인을 벤치마크 가능케한다.
- 게임은 시뮬레이션이기 때문에, 컨트롤을 정확하게 할 수 있으며, 규모를 고려해 실행할 수 있다.
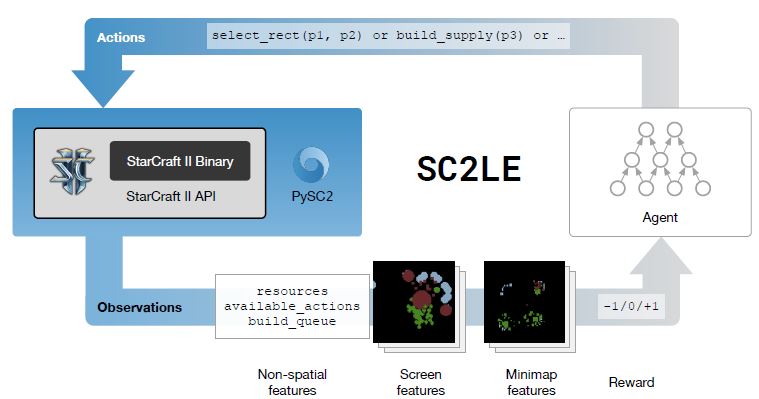
그림 1: 스타크래프트2 학습 환경(SC2LE)의 플러그인된 뉴럴 에이전트 요소를 보여주는 그림.
아마도 강화학습연구를 이끄는 가장 좋은 예는 아타리게임을 이용해 쉽고 반복가능한 실험이 가능케하는 Arcade Learning Envoronment(ALE) 일 것이다.
이러한 표준화된 과제는 최근 AI 연구에서 대단히 유용하다.
ALE환경에서 이용되는 게임 스코어는 논문이나 알고리즘간에 비교될수 있고, 직접적인 관측 및 비교를 가능케한다.
ALE는 슈퍼마리오, 팩맨, 둠, 언리얼토너먼트와 같은 유서 깊은 비디오 게임 AI 벤치마크의 좋은 예일 뿐 아니라 일반적인 비디오 게임에도 적용된다.
스타크래프트1(브루드워)과 같은 RTS는 인공지능을 연구하기에 매력적인 장르이다.
우리는 Ontanon의 서베이 결과, Robertson & Watson의 어버뷰를 추천한다.
이와 같은 많은 연구 결과들는 게임의 특정 면(ex: 빌드오더, 마이크로 컨트롤)에 집중하거나 특정 AI 테크닉(ex: MCTS planning)에 집중한다.
우리는 전체 게임을 풀어나가는 end-to-end RL 접근방법을 알지 못한다.
다루기힘든 RTS의 풀버전게임은 엄청난 양의 인풋, 아웃풋 공간 뿐 아니라, sparse reward structure(ex: 게임 결과)으로 인해 해결하기 벅차 보인다.
일반적인 스타크래프트 API는 BWAPI와 멀어지고 wrappers와 연관된다.
AI 연구에 의해 RTS의 간소화된 버전이 개발되었는데, 특히 microRTS, 최근에는 ELF가 주목할만하다.
또한 학습기반 에이전트는 리플레이 데이터를 통해 micro-management mini-game을 explore 하거나 게임 결과를 학습하고, 빌드오더를 학습한다.
3.스타크래프트2 가상환경
SC2LE 릴리즈를 통한 본 논문의 가장 큰 기여는 스타크래프트2를 연구 환경으로 노출시키는 것이다.
릴리즈는 리눅스 스타크래프트2 바이너리, 스타크래프트2 API, PySC2로 구성되어있다.
스타크래프트2 API는 프로그램적인 컨트롤을 허용한다.
API는 게임 시작, 관측, 행동 취하기, 리플레이 리뷰에 활용된다.
노멀 게임에서의 API는 윈도우와 맥OS에서는 사용가능 한 반면,
리눅스에서는 특히 머신러닝과 분산 처리 케이스에 대해 제한적이고 근본없는 빌드를 제공한다.
API를 이용하여 우리는 PySC2를 개발했는데, 이것은 RL 에이전트에 대해 최적화된 오픈 소스 환경이다.
PySC2는 스타크래프트2 API를 커버하는 파이썬 환경인데, 이는 파이썬 강화학습 에이전트와 스타크래프트2간의 상호작용을 쉽게끔한다.
PySC2는 행동과 관측을 정의하며, 랜덤 에이전트와 스크립트 에이전트의 다루기 힘듦을 포함한다.
그것은 또한 미니게임과 에이전트가 보고, 할수 있는 것을 파악하기 위해 시각화툴을 포함한다.
스타크래프트2는 초당 시뮬레이션 16(at normal speed), 22.4(at fast speed)를 업데이트했다.
이 게임은 확정적이지만, 다소 허울뿐인 랜덤성을 가지고 있다.
두가지 메인 랜덤 요소는 무기속도와 업데이트 순서이다.
이러한 랜덤성은 랜덤시드 셋팅을 통해 제거되거나 완화시킬수 있다.
자, 이제 이 논문에서 이용하는 환경을 알아보도록하자.
3.1 전체 게임 묘사와 보상 구조
스타크래프트2 1vs1 게임에서, 양쪽 진영은 자원, 경사로, 입구, 섬과같은 요소들과 함께 시작한다. 게임에서 승리하기 위해 유저가 해야할 것은
- 자원(미네랄, 가스)을 축적
- 생산 건물을 짓고,
- 군대를 모으고,
- 상대방 건물을 전멸 시킨다.
한 게임은 보통 몇분에서 길면 한시간까지 이어지고,
게임 초반에 선택하는 행동들, 어떤 건물이나 유닛을 생산할 지는 장기적 결과를 가져온다.
플레이어는 자신의 유닛이 존재하는 부분만 맵으로 확인할 수 있기 때문에 불완전한 정보를 가지고 진행한다.
만약 상대방 전략을 파악하고 싶다면 플레이어는 자신의 유닛을 상대방쪽으로 정찰 보내야한다.
섹션 후반에 설명하겠지만, 행동공간은 꽤 유니크하고 도전적이다.
대부분의 플레이어는 온라인을 통해 다른 사람을 상대로 플레이한다.
그 중 가장 인기있는 것은 1v1게임이지만 2v2, 3v3, 4v4 같은 팀플레이도 가능하며 두 팀 이상끼리 싸우는 것도 가능하다.
이 중 우리는 스타크래프트에서 가장 유명한 1v1 게임에 집중할 것이지만, 향후 더욱 복잡한 상황까지 고려할 것이다.
스타크래프트2는 자체 AI를 가지고 있는데 이 자체 AI는 손수 제작된 규칙의 집합이고,
총 10단계의 난이도를 가지고 있다.(가장 강력한 세 단계는 자원을 더 많이 가지고 시작하거나 맵 전체를 볼 수 있는 기능으로 무장되어있다.)
불행히도, 자체 AI의 전략의 선택폭은 좁은 편이다.
쉽게 말해서, 자체 AI는 쉽게 이길 수 있으므로, 플레이어는 쉽게 흥미를 잃게 된다.
그럼에도 불구하고, 자체 AI는 베이스라인에서 시작할 때(section4, 5에서 설명), 첫 번째 도전자로서 꽤 합당하다.
그들은 막무가내로 플레이하지 않으며, 적은 계산량으로 플레이하고, 상대방과 비교했을때 일관적인 베이스라인을 제공한다.
우리는 두가지 보상 구조(reward structure)를 정의한다.
셋으로 이루어진 1(win) / 0(tie) -1(loss) 는 게임이 끝나고 블리자드 스커어와 함께 얻게 된다.
이 보상은 게임 플레이 동안에는 쭉 0점이다.
이 승리/무승부/패배 점수는 우리가 관심있는 실제 보상이다.
원래 블리자드스코어는 게임이 끝난 후 플레이어 스크린에서 확인 가능한데,
우리는 실행 중인 게임에서 각 스텝마다 강화학습의 보상으로 이용되는 블리자드스코어에 항상 접근 가능하다.
그것은 현재 자원의 합과 업그레이드 상황, 현재 살아있는 유닛과 건물을 이용해 계산된다.
즉, 플레이어의 누적된 보상은 자신의 자원을 통해 증가하고, 유닛이나 건물을 잃을 때 감소하며,
그 외에 생산중인 유닛, 건설중인 거물, 업그레이드 중인 업그레이드 같은 요인들은 보상에 영향을 미치지 않는다.
블리자드스코어는 플레이어 중심적이므로 제로섬이 아니며, 승리/무승부/패배 점수에 비해 덜 sparse 하다.
또한 승리나 패배와 상관관계가 있다.
3.2 관측
스타크래프트2는 3D 렌더링 그래픽 게임엔진을 이용한다.
전체 환경을 시뮬레이션 하는 게임엔진을 사용하는 반면, 스타크래프트2 API는 RGB 픽셀을 렌더링 할 수 없다.
그러나 사람이 플레이하는 동안 RGB 이미지를 추상적인 방법으로 feature layers는 만들수 있고,
이것은 스타크래프트2의 핵심 공간적, 그래픽적 개념을 표현할 수 있다.(Figure2 참고)

Figure2: PySC2 뷰어는 사람이 해석 가능한 뷰를 왼쪽에서 보여주고, 피쳐레이어의 칼러 버전을 오른쪽에서 보여준다.
예를 들어, 지형 높이, 전장안개, 크립, 카메라위치, 플레이어 진영은 피쳐레이어에서 탑 부분에서 볼 수 있다.
해당 영상은 http://youtu.be/-fKUyT14G-8 에서 볼 수 있다.
그러므로, 피쳐레이어의 메인 관측은 $N \times M$ 픽셀로 나타나며 $N = M$ 으로 설정 가능하다.
각각의 레이어는 인게임에서 특별함을 나타낸다. 예를들어 유닛 타입이나, 히트 포인트, 소유자, 가시성이 그것이다.
이 중에는 스칼라로 표현되는 것(히트 포인트, 지형 높이)도 있고, 카테고리로 표현되는 것(가시성, 유닛타입, 소유자)도 있다.
피쳐레이어에는 미니맵과 스크린 두가지 셋이 있다.
미니맵은 전체 판을 대략적인 표현으로 나타내고,
스크린은 플레이어가 스크린에서 볼 수 있고 행동을 실행할 수 있는 전체 판의 일부분을 세부적인 뷰를 통해 확인 가능하게 한다.
소유자나 가시성 같은 피쳐들은 스크린과 미니맵 두가지 모두에서 확인 가능하고, 유닛 타입이나 히트 포인트는 오직 스크린에서만 확인 가능하다.
모든 관측이 제공되는 환경 문서를 참고하기 바란다.
스크린과 미니맵 뿐 만 아니라, 휴먼 인터페이스는 다양한 비공간(non-spatial) 관측을 제공한다.
미네랄이나 가스가 얼마나 모였는지, 현재 이용 가능한 행동 집합(물론 이것은 게임 상황에 따라 달라진다),
선택한 유닛의 자세한 정보, 예정된 빌드, 수송선에 실려있는 유닛 등을 제공한다.
이러한 관측은 PySC2에서 또한 확인 가능하며, 환경 문서에 소개되어있다.
스크린의 전체 게임은 고해상도 풀 3D 카메라 시점으로 렌더링 되어있다.
이것은 유닛이 스크린에서 높아져서 작아지거나 정면보다 뒤에서 볼 수 있는 세밀한 관측을 가능케한다.
쉽게 말하면, 피쳐레이어는 카메라를 통해 렌더링 되어있는데, 탑다운 정사영을 사용한다.
즉, 피쳐레이어의 각 픽셀은 실제 영역과 정확히 같은 양이고,
결과적으로 그들이 어느 뷰에 있던 상관없이 모든 유닛은 같은 크기가 된다.
불행히도 이 말은 피쳐레이어 렌더링이 인간이 보는 시야와 일치하지 않는다는 것을 뜻한다.
에이전트는 뒤(back) 보다는 앞(front)을 많이 보게 된다.
이것은 리플레이에서 하는 인간의 완벽한 행동 재현을 뜻하지는 않는다.
향후 릴리즈에서 우리는 RBG 픽셀로 에이전트가 플레이 할 수 있는 렌더링된 API를 제공할 것이다.
이것은 로우 픽셀, 픽셀레이어로 학습 효과를 연구할 수 있게 하고 실제 유저의 플레이와 더욱 흡사하게 한다.
그 동안, 우리는 피쳐레이어를 통해 에이전트는 과하게 핸디캡이 주어지지 않았다는 것을 확인하며 게임플레이를 하였다.
비록 게임 플레이 경험이 명백히 바뀌었는데, 해상도 $N, M \geq 64$ 는 저글링과 같은 작은 유닛을 컨트롤 할 수 있을 정도로 충분하다는 것을 발견했다.
이 글을 읽고있는 독자는 Figure2와 pysc2_play를 통해 직접 체험 해 볼 수 있다.
3.3 행동
우리는 휴먼 인터페이스를 최대한 가깝게 구현하고자 행동 공간 환경을 디자인 한다.
다른 강화학습 환경에서 아타리 같은 전통적인 방법을 유지하는 반면,
Figure3은 플레이어와 에이전트의 짧은 행동 순서를 보여준다.
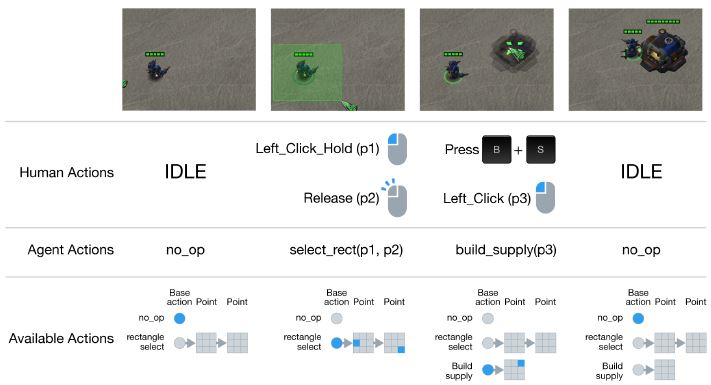
Figure3: 스타크래프트2에서 실제 유저 행동과 PySC2에서 표현되는 행동의 비교. 우리는 행동공간을 실제 유저 행동에 최대한 가깝게 디자인하였다. 첫 번째 행은 게임 스크린을 보여주고 두번째 행은 실제 유저 행동을 보여주며, 세번째 행은 PySC2에서의 논리적 행동을 보여주고, 마지막으로 네번째 행에서는 행동 $a$가 PySC2 환경에서 표현되는 것을 보여준다. 첫 두 열은 ‘build supply’ 행동을 하지 않았다는 것에 주목해라, 이것은 첫번째 선택한 에이전트에 아직 가능한 상황이 아니다.
인게임에서 많은 기본적인 동작은 복합적인 행동이다.
예를 들어, 유닛을 맵을 가로질러서 이동시킨다고하면,
플레이어는 m 키를 누르고 나서 해당 행동을 큐에 넣기위해 shift 키를 누를수 있다.
그러고나서 스크린이나 미니맵에 원하는 지점을 찍을 수 있다.
에이전트에 세가지 분리된 행동을 시키기 위해 3개의 키보드나 마우스 입력을 요청하는 대신
아주작은 복합적인 함수 행동을 시킬 수 있다 : $\texttt{move_screen}(queued, screen)$.
공식적으로, 행동 $a$는 function identifier $a^0$과 $a^1, a^2,…,a^L$ arguments의 순서 구성으로서 나타낼 수 있다.
예를 들어, 마우스 드래그를 통해 여러 유닛을 선택하는 상황을 생각해보자.
의도된 행동은 $\texttt{select_rect}(\texttt{select_add}, (x^1, y^1), (x^2, y^2))$이다.
첫번째 argument $\texttt{select_add}$는 바이너리이다.
다른 argument 들은 좌표공간에 정의된 정수이다.
그들의 범위(range)는 관측의 해상도와 같다.
이 행동은 환경으로부터 $\texttt{select_rect}, [[\texttt{select_add}],[x^1, y^1],[x^2, y^2]]]$ 형태로 제공된다.
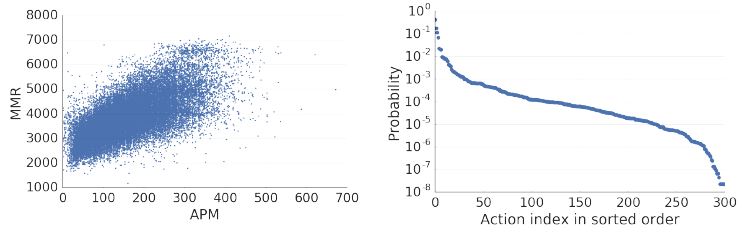
full 행동공간을 표현하기 위해 우리는 13 종류의 argument를 가진 대략 300개의 행동 함수 식별자를 정의한다.(바이너리부터 불연속 2D 스크린의 특정지점까지)
PySC2를 통한 행동 묘사 및 자세한 사항은 환경 문서를 참고하길 바라며, Figure3는 행동순서의 예이다.
스타크래프트에서는 모든 게임에서 모든 행동이 가능한 것은 아니다.
예를 들어, 무브 커맨드는 유닛을 선택했을 때만 가능하다.
유저는 스크린에서 어떤 행동이 가능한지 볼 수 있다.
이와 비슷하게, 에이전트의 각 스텝에서 관측을 통해 행동가능 리스트를 제공한다.
불가능한 행동을 취하는 것이 에러로 인식되므로 에이전트는 행동가능리스트 중에 행동을 선택하게 된다.
실제 유저는 30 ~ 300 APM(손빠르기)를 가지는 데,
유저의 스킬에 따라 증가하는 경향이 있으며, 프로게이머의 경우 500 APM을 넘는 경우도 있다.
우리 실험에서는 프레임당 8가지 행동을 하게되는데 이는 180 APM에 해당하며 이는 중수 정도에 해당한다.
이렇게 미리 환경을 디자인하는 것은 더욱 복잡한 RL 에이전트를 개발하는데 도움이 된다. 특히, 픽셀사이즈 피쳐 레이어 인풋 공간과 인간같은 행동 공간은 에이전트 기반 뉴럴 네트워크를 사용하기 자연스럽다. 이것은 다른 최근 논문과는 반대되는 사항인데, 최근 논문들은 유닛 하나하나에 기반하며 행동들 또한 유닛별로 따로 접근한다. 각각의 인터페이스 스타일에는 장점이있는 반면, PySC2의 장점은 다음과 같다.
- 실제 유저 리플레이를 통한 학습은 다른 스타일에 비해 간단하다.
- 비현실적/인간을 뛰어넘는 APM을 요구하지 않는다.
- 이러한 UI로 디자인된 게임과 높은 수준의 결정, 경제 관리, 병력 컨트롤 사이의 밸런스는 게임을 더욱 흥미롭게 만든다.
3.4 미니게임 묘사
풀 게임 플레이에서 고립된 상황에서의 요인을 조사 하고 더욱 부드러운 스텝을 제공하기 위해, 우리는 몇몇 미니게임을 개발했다.
미니게임은 명확한 보상구조를 가지고 있는 몇가지 행동이나 게임기법을 위한 테스트 목적으로 제작된 작은 맵에서 시나리오에 집중한다.
보상이 승리/패배/무승부인 풀 게임과는 달리, 미니게임의 보상구조는 특별한 행동이다.(SC2Map 파일에 정의 되어있다)
우리는 커뮤니티에 강력한 스타크래프트 맵에디터를 이용한 빌드 수정이나 새로운 미니게임을 하도록 권장했다.
이것은 단지 작은 영역에서 도전을 계획 한 것 이상을 가능케했다.
그것은 서로다른 연구자에게 동일한 설정과 평가, 평가 점수의 직접적인 비교가 가능하도록 했다.
제한된 행동 셋은 커스텀 보상 함수와 시간 제약이 쉽게 공유 가능하도록 .SC2Map 파일에 결과에 직접적으로 정의 되어 있다.
그러므로 우리는 유저가 에이전트쪽에 커스터마이징된 것보다 새롭게 정의된 업무를 이용하는 것을 권장한다.
다음은 우리가 릴리징한 일곱가지 미니게임이다.
- MoveToBeacon: 에이전트는 마린 1기로 시작하는데 비콘에 도착할 때마다 마린 숫자가 하나씩 늘어난다. 이 맵은 trivial greedy stragegy 유닛 테스트이다.
- CollectMineralShards: 에이전트는 마린 2기로 시작하고 그들을 선택해서 맵 곳곳에 퍼져있는 미네랄로 이동시킨다. 좀 더 효율적으로 움직일수록 높은 스코어를 기록한다.
- FindAndDefeatZerglings: 에이전트는 마린 3기로 시작하고 맵을 탐험하여 저글링을 격파해야한다. 이것은 카메라 움직임과 효율적인 탐험을 요구한다.
- DefeatRoaches: 에이전트는 마린 9기로 시작하고 바퀴 4기를 격파해야한다. 바퀴를 모두 격파시키면 5기의 마린이 추가되고 4기의 바퀴가 생성된다. 바퀴하나당 보상은 +10에 해당하고 마린이 하나 죽을 때마다 보상은 -1이다. 마린을 죽지 않고 잘 관리해야하고 바퀴를 전멸시켜야한다.
- DefeatZerglingsAndBanelings: 적이 저글링과 맹독충이라는 사실을 제외하곤 바퀴 미니게임과 동일하다. 상대방을 죽일때마다 +5의 보상이 주어진다. 이 게임은 상대방이 서로 다른 능력을 가지고 있으므로 다른 전략이 요구 된다.
- CollectMineralsAndGas: 에이전트는 제한된 베이스로 시작하고 제한된 시간에서 자원 수급으로 보상이 결정된다. 성공적인 에이전트는 일꾼을 더 많이 생산하여 자원 수급률을 증가시킨다.
- BuildMarines: 에이전트는 제한된 베이스로 시작하고 마린을 생산함으로써 보상을 받는다. 이를 위해 일꾼을 생산하고 자원을 수급하고 서플라이 디폿, 배럭을 건설해야하며 그 이후 마린을 생산해야한다. 이 목표를 달성하기 위해 최소한의 행동 셋으로 행동 공간을 제약시킨다.
모든 미니게임은 시간 제한이 정해져 있고 더 자세한 사항은 https://github.
com/deepmind/pysc2/blob/master/docs/mini_games.md을 참고하길 바란다.
3.5 Raw API
스타크래프트2는 raw API를 가지고 있는데 이는 브루드워 API(BWAPI)와 비슷하다.
이 경우, 관측은 맵상에서 볼수있는 유닛과 그 특징(유닛 타입, 소유자, 좌표, 체력 등)으로 구성되어 있다.
전장안개 개념은 여전히 유효하지만, 카메라는 존재하지 않으므로 너는 모든 유닛을 동시에 볼 수 있다.
이것은 간소화하고 더 정확한 묘사이지만 인간이 게임을 어떻게 인지하는 지와 부합하진 않는다.
실제 유저와의 비교목적을 위해 이것은 추가적인 정보를 획득가능하므로 치팅으로 간주된다.
raw API를 이용해 유닛 특징에 따른 행동 컨트롤을 한다.
행동이 정해지기 전에 유닛을 선택할 필요는 없다.
이것은 휴먼 인터페이스가 제공하는 것보다 더욱 정확한 행동을 허용하고, API를 이용해 인간을 뛰어넘는 행동 가능성을 초래한다.
비록 우리는 raw API를 머신러닝 연구에 사용하진 않지만 다른 종류의 지원(스크립트된 에이전트나 시각화)을 하기 위해 포함된다.
3.6 Performance
우리는 실제 시간보다 빠르게 가상 환경을 실행시킨다.
관측은 맵의 복잡도, 스크린 해상도, 각 행동마다 렌더링 되어있지 않은 갯수, 쓰레드 수 같은 몇가지 요인들에 의해 스피드가 렌더링 되어 있다.
복잡한 맵(full 레더 맵)에 대해 계산은 시뮬레이션 스피드에 의해 정해진다.
행동을 덜 할수록, 더 적은 렌더링 프레임이 허용되고 계산량이 줄어들며,
킥(kick)이 줄어드는데 이는 각 행동마다 8가지 스텝 이상을 뜻한다.
주어진 시간이 적은 것은 높은 해상도 렌더링을 상하게 하지 않는다.
병렬 쓰레드에서 더욱 많은 인스턴스를 실행시키는 것이다.
간단한 맵(예: CollectMineralShards)에 대해 월드 시뮬레이션은 매우 빠르므로, 관측 지역 랜더링을 하게 된다.
이 경우, 매 행동시 프레임을 증가시키고 해당도를 감소시키는 것은 큰 효과를 가지고 있다.
바틀넥은 파이썬 인터프리터가 되고 싱글 인터프리터의 4개 쓰레드의 이점을 무효화 시킨다.
$64 \times 64$ 해상도와 행동별 8프레임의 비율로 행동하는 것, 컴퓨터 시간 초당 레더맵의 싱글 쓰레드 200-700 스피드는 실제시간보다 더 빠르게 진행된다. 게임 스테이지, 플레이 중인 유닛 수, 컴퓨터가 그것을 실행시키는 것 같은 여러 요인에 의해 정확한 스피드가 정해진다. CollectMineralShards에서는 컴퓨터 시간 초당 1600-2000 게임 스텝이 허가 되도록 셋팅되어 있다.
4. Reinforcement Learning: Baseline Agents
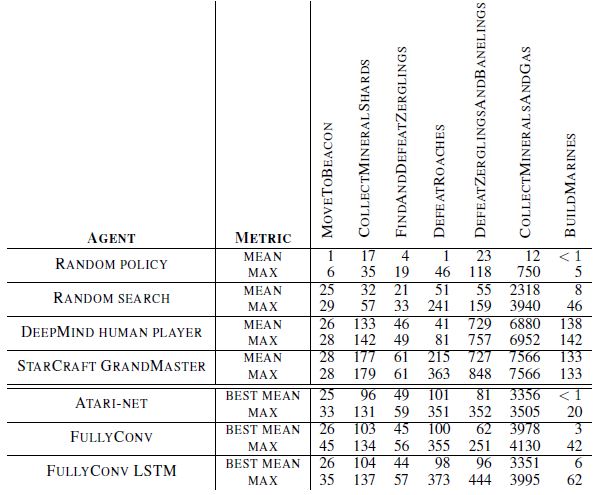
본 섹션은 맵의 어려움을 측정 제공하는 베이스라인 결과를 제공하고, 미니게임에서 유용한 정책을 학습할 뿐 만 아니라 여전히 많은 도전 과제가 남아있는 RL 알고리즘을 입증한다. 우리는 추가적으로 두명의 실제 유저(딥마인드 게임 테스터(초보수준), 스타크래프트 그랜드마스터(프로 수준))를 통해 스코어를 제공한다.
4.1 Learning Algorithm
강화학습 에이전트의 코어는 모수 $\theta$와 정책 $\pi$로 정의된 심층 뉴럴 네트워크로 구성되어있다.
타임 스텝 $t$에서 에이전트는 관측값 $s_t$를 받고, 확률 $\pi_\theta(a_t|s_t)$로 행동 $a_t$를 선택하고,
해당 환경에서 보상 $r_t$을 받게 된다.
에이전트의 목표는 보상 $G_t = \sum_{k=0}^{\infty}\gamma^{k}r_{t+k+1}$, ($\gamma$ 는 할인율)을 최대화 시키는 것이다.
표기법의 명확성에 대해 우리는 정책은 관측 $s_t$에 의해 정해지고,
모든 이전 상태(states)이 주어졌을때 아래에 서술하고 있는 히든 메모리 상태를 통해 일반성의 손실은 없다.
정책의 모수는 Mnih논문에 기술된 것과 같이 Asynchronous Advantage Actor Critic(A3C)를 통해 학습된다.
이것은 다양한 환경에서의 최신 결과를 보여준다.
이 정책은 gradient method 정책을 사용하는데 approximate gradient ascent $E[G_t]$를 수행한다.
A3C 경사로는 다음과 같다.
$v_{\theta}(s)$는 같은 네트워크에서의 extected return $E[G_t|s_t = s]$의 value function estimate이다. full return 대신, 우리는 n-step 리턴 $G_t = \sum_{k=0}^{n}\gamma^{k}r_{t+k+1} + \gamma^{n}v_{\theta}(s_{t+n})$을 사용하고, $n$은 하이퍼 파라미터이다. 마지막 부분은 큰 엔트로피에 대해 정규화된 정책이고, 이것은 exploration을 증진시키고 $\beta$ 와 $\eta$는 서로다른 손실 요소의 중요성을 상쇄시키는 하이퍼 파라미터이다.
4.2 Policy representation
섹션 3에 서술된 것 처럼, API는 함수 식별자 $a^0$ 과 argument 집합이 포함된 내재된 리스트 $a$를 통해 행동을 나타낸다. 모든 argument는 스크린에서 픽셀 좌표를 포함하고, 미니맵은 discrete이고 정책 $\pi(a|s)$의 naive 파라미터화는 $a$에 관한 결합 분포를 명시하기 위해 심지어 낮은 spatial 해상도에 대해서도 수백만개의 값을 요구한다. 대신에, 우리는 auto-regressive 방법과 체인룰에 대한 정책을 나타낼 것을 제시한다.
\[\pi(a|s) = \Pi_{l=0}^{L}\pi(a^{l}|a^{<l},s)\]이 표기는 만약 효율적으로 나타내면 각 argument $a^l$에 대한 결정 순서에 대해
전체(full) 행동 $a$를 선택하는 문제를 변형하는데 확실히 간단하다.
함수 식별자(function identifier) $a^0$에 대해 요구되는 arguments L의 숫자는 다르다.
$\texttt{move_screen}(x,y)$같은 것은 argument를 요구하지만, 어떤 행동(예를들어 no-opaction)은 어떤 argument도 요구하지 않는다.
이러한 변동성을 나타내는 짧은 행동 순서를 참고하고 싶다면 Figure3를 참고하라.
어떤 것은 체인룰이 적용되는 순서를 정의하기 위해 argument에 대해 임의의 순열을 사용할 수 있다.
그러나, 스크린에서 어디를 클릭할 지에 대한 결정은 자연스럽게 클릭의 목적, 즉 호출되는 함수의 식별자에 의존한다.
대부분의 실험에서 우리는 독립적으로 sub-action 모델링에 충분하다는 것을 발견지만,
우리가 처음 함수식별자, 범주형 argument, 그리고 관련있다면 픽셀 좌표에 의해 선택되는 순서와 관련된 auto-regressive 정책을 탐구한다.
불가능한 행동은 에이전트에의해 선택되지 않음을 확실히 하기 위해,
우리는 $a^0$의 함수식별자 선택을 드러내고,
샘플링된 오직 적절한 부분함수와 플레이어가 랜덤으로 어떻게 UI상의 버튼을클릭하여 흉내낸다.
우리는 행동과 $a^0$에 대한 확률 분포를 renomalising 한다.
4.3 Agent Architectures
이 섹션에서는 합리적인 베이스라인을 생산하기 위함으로 몇가지 에이전트 아키텍쳐를 제시한다.
우리는 참고자료 20, 19를 바탕으로 아키텍쳐를 설립했고,
그것을 특정 행동 공간의 특정 환경에 맞추었다. Figure 4는 제안된 아키텍쳐를 묘사한다.
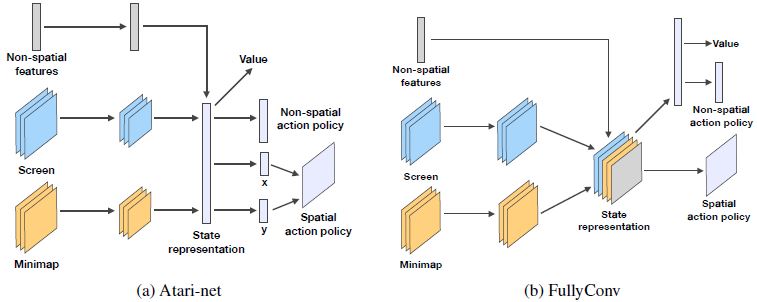
Figure4: 이 논문의 베이직 에이전트의 네트워크 아키텍쳐
Input pre-processing 모든 베이스라인 에이전트는 같은 인풋 피쳐 레이어의 전처리(pre-processing)를 공유한다.
우리는 $1 \times 1$ convolution을 따르는 channel dimension의 one-hot 인코딩을 이용하는 것과 같은
연속형 공간의 범주형 value를 포함하는 모든 피쳐 레이어를 끼워넣었다.
우리는 또한 히트 포인트나 미네랄이 상당히 높은 값을 가지는 수치형 피쳐에 대해 로그 변환함으로써 리스케일링 했다.
Atari-net Agent 첫 베이스라인은 아타리 벤치마크와 딥마인드 연구소 환경에 이용되는 아키텍쳐에 가까운 적용이다.
그것은 참고자료 19에 있는 합성 네트워크로 스크린과 미니맵 피쳐 레이어를 처리한다.
(각각 사이즈 8,4와 stride 4,2의 16, 32 필터의 두 레이어)
non-spatial 피쳐 벡터는 tanh non-linearity의 선형 레이어로 가공되었다.
결과는 ReLu activation로 이루어진 선형 레이어를 통해 보내진다.
마지막으로, 결과 벡터는 인풋에서 행동 함수 id $a^0$와
각각의 행동 함수 argument ${ a^l }{l=0}^{L}$의 결과 정책 선형레이어로 이용된다.
FullyConv Agent Atari-net 베이스라인 기반의 강화학습에 대한 합성 신경망은 대체로 인풋의 각 레이어에 대해 spatial resolution을 줄이고,
궁극적으로 완전히 연결된 레이어를 버림으로써 마무리 짓는다.
이것은 spatial information이 행동이 추론되기 전에 추상화 시키는 것을 허용한다.
하지만 스타크래프트에서의 주요 도전 과제는 spatial action(스크린이나 미니캡을 클릭하는 것)을 추론하는 것이다.
이러한 spatial action은 인풋으로써 같은 공간내에 있는데, 이것은 인풋의 spatial structure를 버리는 것에 해롭다.
우리는 해상도가 보존되는 합성 레이어의 순서를 통해 직접적으로 spatial action을 예측하는 완전한
합성 신경망 에이전트(fully convolutional network agent)를 제안한다.
우리가 제안하는 신명망은 모든 레이어에 대해 no stride이고 padding을 이용하므로,
인풋의 공간 정보 해상도를 보존한다.
간단하게 말해서, 우리는 스크린과 미니맵 인풋은 같은 해상도라고 가정한다.
우리는 분리된 각각 $5 \times 5$, $3 \times 3$ 사이즈의 16, 32 필터로 된 2-레이어 합성 신경망을 통해 스크린과 미니맵을 관측한다.
상태 표시는 스크린과 미니맵 아웃풋의 접합 뿐만 아니라, broadcast 벡터 통계, 채널 차원(channel dimension)을 통해 형성된다.
범주형 행동(non-spatial)에서 베이스라인과 정책을 계산하기 위해
상태 표시는 처음으로 256 유닛과 ReLU activation으로 된 완전히 연결된 레이어, 완전히 연결된 선형 레이어로 통과 된다.
마지막으로 공간 행동에 대한 정책은 싱글 아웃풋 채널의 상태 표시의 $1 \times 1$ convolution 사용을 통해 획득된다.
이러한 계산을 시각적으로 보기 위해 Figure4를 참고하기 바란다.
FullyConv LSTM Agent 위에 작성된 두 베이스라인 모두 feed-forward 아키텍쳐이고 그러므로 메모리는 존재하지 않는다.
이것이 어떤 테스크에 충분한 반면, 우리는 스타크래프트의 full 복잡성에는 충분하지 못한다고 생각한다.
여기서 우리는 합성 LSTM에 기반한 베이스라인 아키텍쳐를 소개한다.
우리는 위에 언급한 fully-convolutional 에이전트의 파이프라인을 따르고,
미니맵과 스크린 피쳐 채널을 non-spatial 피쳐로 연결한 간단한 합성 LSTM 모듈을 추가했다.
Random agents 우리는 두가지 랜덤 베이스라인을 이용한다. 랜덤 정책은 아주 큰 행동공간에서 성공적인 에피소드의 실패의 어려움을 강조한 모든 타당한 행동들 중 균일하게 선택하는 에이전트이다. 랜덤 서치 베이스라인은 많은 독립이고 랜덤하게 초기화된 정책 네트워크(낮은 softmax 온도는 결정적인 행동을 유도한다)를 취함으로써 작업한다. 또한 각각의 20개의 에피스드를 평가하고 가장 높은 평균 점수를 유지한다. 이것은 행동공간보다 정책공간에서 샘플링함으로써 상호보완적이다.
4.4 Results
A3C에서 우리는 trajectory를 자르고 신경망의 $K=40$ forward step 이후 혹은 terminal signal을 받은 후 backpropagation을 실행한다. 최적화 과정은 공유된 RMSProp을 이용한 64 비동기 쓰레드를 작동시킨다. 각 방법에 대해 우리는 100번의 실험을 수행하고 각각 랜덤하게 샘플링된 모수를 이용한다. 학습율은 $10^{-5}, 10^{-3}$ 구간에서 샘플링했다. 학습율은 모든 에이전트에 대해 샘플링된 값을 초기율의 반으로 만듦으로써 선형으로 강화시켰다. 우리는 행동 함수와 각 행동 함수 argument에 대해 $10^{-3}의 $독립 엔트로피 페널티를 사용했다. 우리는 매 8 게임 스텝에 대해 행동하는 180 APM 과 동등한 고정 비율을 사용했다.
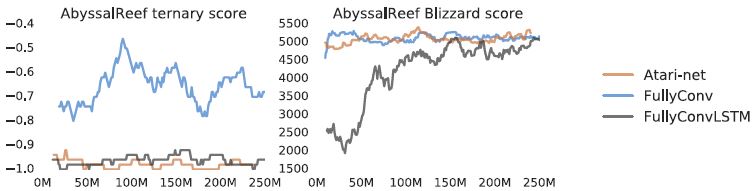
4.4.1 Full Game
전체 게임에 대한 실험에서 우리는 프로페셔널 경기 뿐 만 아니라,
온라인 랭크게임에서 사용되는 Abyssal Reef LE 레더 맵을 선택했다.
에이전트는 가장 쉬운 AI를 상대로 테란 대 테란으로 경기에 임한다.
에피스도가 종료되고 무승부가 명확할 때 최장 게임 시간은 30분으로 설정했다.
실험 결과는 Figure5에서 확인 가능하다.
당연하게도, sparse 세번째 보상으로 훈련된 에이전트가 full game에 대해 실행가능한 전략을 개발 할 수는 없었다.
메모리 없는 fully convolutional 아키텍처에서 가장 성공적인 에이전트는
테란의 능력인 건물 옮기기를 통해 공격 범위를 벗어남으로써 연속적인 손실을 방지했다.
블리자드 스코어로 훈련된 에이전트는 일꾼을 산만하게 하는 것을 피하는 하찮은 전략으로 수렴했고,
스코어에서 안정적인 개선을 유지했다.
그러므로, 대부분의 에이전트의 점수는 초반 자원을 캐는 과정에서 건물을 더 짓거나 유닛을 생산하는 것 없이 심플하게 유지했다.
(이 행동은 아래서 언급하는 미니게임에서도 관찰되었다.)
스타크래프트2의 전체 게임에서 이러한 결과는 흥미로웠고
특히 실제 유저의 리플레이와 같은 다른 정보를 이용하지 않는 면에서 RL 도메인으로써 흥미로웠다.
4.4.2 Mini-Games
섹션 3에서 언급한 것과 같이 한 에이전트는 미니게임을 정의함으로써 게임의 일부분에 집중함으로써 전체 게임의 복잡성을 피할 수 있다.
우리는 에이전트를 각 미니게임에 대해 학습시켰다.
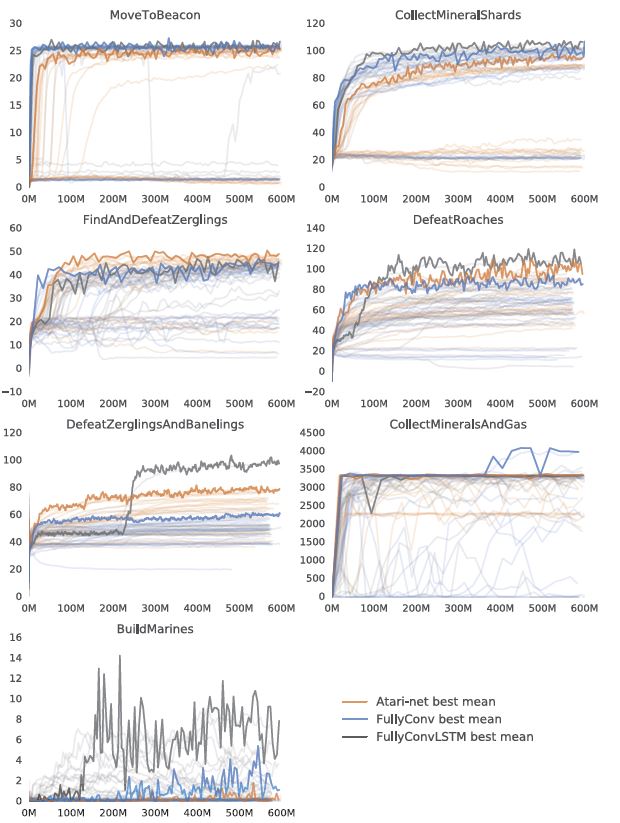
통합된 학습 결과는 Figure6에서 볼수 있고 휴먼 베이스라인과의 최종결과 비교는 Table1에서 확인 가능하다.
영상으로 확인하고 싶다면 https://youtu.be/6L448yg0Sm0 을 참고하길 바란다.
종합적으로 fully convolutional 에이전트는 non-human baseline에서 최고의 퍼포먼스를 보여준다.
다소 놀랍지만 Atari-net 에이전트는 FindAndDefeatZerglings, DefeatRoaches and DefeatZerlingsAndBanelings 와 같은
미니게임 전투에서 꽤 강력한 경쟁력을 보여준다.
CollectMineralsAndGas에 대해선 오직 베스트 Convolutional 에이전트만이
초기 자원 수입을 일꾼을 추가 생산하고 미네랄에 붙임으로써 증가시키는 학습이 가능했다.
우리는 BuildMarines가 전략을 요구하는 미니게임이고 스타크래프트 전체게임에 가장 유사하다고 생각했다.
Atari-Net이 각 에피소드에서 연속적인 마린 생산을 학습하지 못한 반면,
이 게임에 대한 베스트 결과는 FullyConv LSTM 과 Random Search에 의해 달성되었다.
해당 맵에 대한 행동공간 제한 없이는 미니게임을 학습하는게 어렵다는 사실을 주목해야한다.
가장 간단한 기법과 반응을 요구하는 MoveToBeacon을 제외하고,
그랜드마스터 유저를 상대로 비교할때, 모든 에이전트는 부분최적화로(sub-optimally) 수행된다.
그런데 DefeatRoaches와 FindAndDefeatZerglins와 같은 게임에서는 딥마인드 게임 테스터를 상대로 fared well 했다.
베이스라인 에이전트의 결과는 비교적 간단한 미니게임이 우리가 새로운 연구에 도전하기에 흥미롭다는 것을 입증한다.
5 Supervised Learning from Replays
전문가 수준이거나 아마추어 수준의 게임 리플레이는 새로운 전략을 배우고 인게임에서 치명적인 실수를 찾아내거나
단순히 다른 사람의 플레이를 보는 것만으로도 엔터테인먼트적인 면에서도 중요한 자원이다.
리플레이는 감춰진 정보 때문에 특히 스타크래프트에서 중요하다.
전장안개는 당신의 유닛이 적의 영역에 있지 않는 한 모든 적의 유닛을 가린다.
그러므로 전문적인 유저들 사이에서 모든 게임을, 심지어 자신이 이겼을 때도, 복습하고 연습하는건 전형적인 연습이다.
리플레이와 같이 supervised data를 사용하거나 실제 유저가 직접 입증하는 것은 바둑이나 아타리 게임과 같은 로보틱스 분야에서 성공적이었다.
기본 행동을 통해 정책을 훈련하는 것이 아닌 빌드오더를 발견하는 방법은 스타크래프트1에서 사용되었다.
스타크래프트2는 점점 증대되는 실제 유저 리플레이를 통해 기회를 얻고 학습한다.
스타크래프트1의 리플레이를 모으는데 핵심적이고 표준화된 메커니즘은 없지만,
많은 수의 스타크래프트2 게임은 블리자드 1vs1 래더에서 쉽게 이용가능하다.
또한 더 많은 게임이 상대적으로 안정적인 초보자 수를 추가시키는 것도 가능하다.
리플레이를 통한 학습은 부트스트랩(bootstrap)이나 완전 강화학습에 유용하다.
격리된 상태에서, 그것은 장기 상관관계를 다루는 순차적 모델링이나 메모리 구조에 대해 벤치마크를 제공한다.
실제로, 게임을 펼쳐놓고 이해하기 위해선,
한쪽은 많은 타임 스텝에 대해 효율적으로 정보를 통합시켜야한다.
더욱이 부분적인 식별가능성 때문에, 리플레이는 variational autoencoder와 같은 불확실성을 연구하는데 쓰인다.
마지막으로 이 분야에서 결과/행동 예측하는 퍼포먼스를 비교하기 위해서는 RL에 대해 적합한 귀납적 편향의 뉴럴 아키텍쳐가 도움이 될 것이다.
이 섹션의 나머지 부분에서는, 섹션4에서 묘사된 800K 게임을 학습과 value function(즉, 게임관찰로부터 게임의 승리를 예측하는), 정책(즉, 게임 관찰로부터 행동을 예측하는)에 이용하는 아키텍쳐를 이용하는 베이스라인을 제공한다. 게임은 스타크래프트2에서 모든가능한 매치업을 포함한다(즉, 우리는 에이전트가 한 종족만 플레이하는 것에 대해 제한을 두지 않는다)
우리는 게임 결과(1=승리, 0=패배 또는 무승부)와 각 타임스텝에서의 플레이어 행동 모두를 예측하는 dual-headed 네트워크를 훈련시켰다. 네트워크의 body를 공유하는 것은 두개의 손실함수의 무게를 측정할 뿐 만 아니라 value와 정책 예측을 다른 것에 알려주기 위해 필수적이다. 우리는 지도학습 셋팅에서 무승부인 경우는 따로 분리해서 만들지 않았다. 왜냐하면 무승부의 숫자는 1%미만으로 승리나 패배에 비해 매우 낮았기 때문이다.
5.1 Value Prediction
게임의 결과를 예측하는 것은 어려운 일이다.
심지어 스타크래프트2 해설가는 게임의 상태(state)를 거의 전체적으로 알 수 있음에도(양쪽 진영 모두 볼수있음) 종종 예측을 실패한다.
게임의 결과를 정확히 예측하는 Value function을 희망한다. 왜냐하면 그들은 sparse 보상으로 부터 학습의 챌린지를 완화사킨다.
상태가 주어졌을때 잘 훈련된 value function은 게임의 결과를 보기전에 이웃 상태가 장기적으로 더 가치있을 것이라고 제안한다.
지도학습을 위한 셋업은 섹션4에 설명된 Atari-net, FullyConv 처럼 간단한 베이스라인 아키텍쳐로 시작한다. 그 네트워크는 이전의 관측을 고려하지 않는다, 즉, 그들은 싱글 프레임으로부터(이것은 명확히 sub-optimal하다) 결과를 예측한다. 더욱이 관측은 어떠한 독점적 정보도 포함하지 않는다. 에이전트는 각 게임스텝(전장안개가 적용된)을 베이스로 value 예측해야한다. 그러므로 만약 상대방이 비밀스럽게 많은 유닛을 효율적으로 관리한다면 그것은 실수로 그것보다 강하다고 믿는다.(?)
섹션4에 설명된 네트워크는 행동 인식과 argument는 독립적이라고 제안한다.
하지만, 스크린의 한점을 예측하는 정확도는 추가적인 베이스를 건설하는 것과 유닛을 움직이는 것과 같이 주어진 행동에 따라 개선될 수 있다.
그러므로 Atari-net과 FullyConv 아키텍쳐에 추가적으로,
우리는 섹션4.2에 소개된 auto-regressive 정책 인트로덕션을 사용하는 FullyConv를 가지고 있다.
즉, 함수 식별자 $a^0$와 이전에 샘플링된 argument $a^{<l}$을 현재 argument $a^l$을 기반으로 모형의 정책을 사용한다.
네트워크는 스타크래프트2에서 가능한 매치업을 기반으로 200K 스텝의 경사하강법으로 학습된다.
우리는 균일하게 시간대가 퍼져있는 모든 리플레이로부터로부터 얻은 64개의 관측치의 미니배치를 학습시킨다.
관측치는 RL 셋업으로부터 8개의 step multiplier로 샘플링 되었다.
스크린과 미니맵의 해상도는 $64 \times 64$이다.
각각의 관측치는 스크린과 미니맵의 spatial 피쳐 레이어 뿐 만 아니라, 플레이어의 인구수, 미네랄 수집량과 같이
실제 유저가 스크린에서 볼 수 있는 상태를 포함한다.
우리는 리플레이의 90%의 리플레이를 트레이닝 셋으로 사용하고 나머지 10%의 리플레이를 0.5M 프레임으로 고정시켰다.
에이전트 퍼포먼스는 트레이닝 과정을 통해 테스트셋을 이용해 연속적으로 평가되었다.
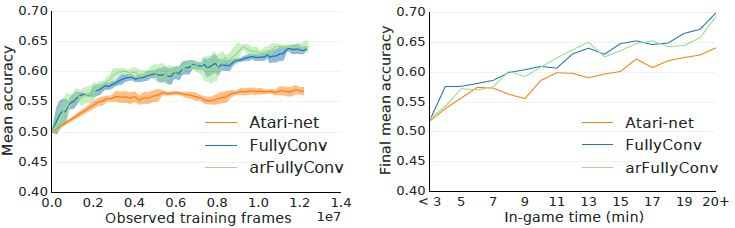
Figure8은 트레이닝 스텝과 게임내 시간 함수로 학습된 모델의 정확도의 평균 정확도를 보여준다. 랜덤 베이스라인은 모든 종족이 잘 밸런싱 되어있기 때문에 대략 시간의 50%로 정정했다. 학습 과정(training progress)에서 FullyConv 아키텍쳐는 64%의 정확도를 달성했다. 또한 게임 과정(game progress)에서 value 예측은 Figure8(오른쪽)에서 보다시피 더욱 정확해졌다. 이것은 이전 스타크래프트1에대한 결과를 반영한다.
5.2 Policy Predictions
value를 예측하기 위한 동일한 네트워크는 유저에의한 행동을 예측하기 위해 분리된 아웃풋을 가진다.
우리는 가끔 정책으로서 네트워크의 이러한 부분을 참고한다. 왜냐하면 쉽게 게임 플레이에 배치 되기 때문이다.
리플레이로부터 실제 유저의 행동을 흉내내기 위한 학습 네트워크를 쓰기위한 많은 구조가 있다.
우리는 섹션4에서의 RL과의 직접적으로 연결되어있는 간단한 접근법을 사용한다.
우리의 정책을 학습시킬때, 우리는 8 프레임의 고정된 step의 관측치를 샘플링한다.
우리는 정책에 대해 학습타겟으로서 각 8프레임이네에 첫번째 행동을 발행한다.
만약 그 기간동안 행동이 없다면, 아무런 효과를 가지지 않는 특별한 행동, 즉, ‘no-op’를 타겟팅 하게 된다.
스타크래프트2를 실제 유저가 플레이할때, 모든 가능한 행동 공간의 오직 하나의 부분공간만이 주어진 시간에 이용가능하다.
예를 들어, “마린 생산하기”는 오직 현재 배럭을 선택했을 때만 가능하다.
네트워크는 이러한 정보는 쉽게 이용가능 하므로, 불법적인 행동 피하기를 학습할 필요는 없다.
그러므로, 학습하는 동안, 실제 유저가 할수 없는 행동은 걸러낸다.
그렇게 하기 위해, 지난 8 프레임에 대해 모든 가능한 행동의 집합을 얻고, 0에 가까운 이용할수없는 모든 행동의 확률을 셋팅하고 적용시킨다.
이전에 언급한 것처럼, 우리는 모든 가능한 매치업을 플레이하기 위해 정책을 학습시킨다.
그러므로, 이론적으로, 에이전트는 어떤 종족이든 플레이 할 수 있다.
그러나, 섹션4에서 연구한 강화학습 에이전트의 일관성을 위해,
우리는 인게임 메트릭을 오직 테란 대 테란 매치업으로 정했다.
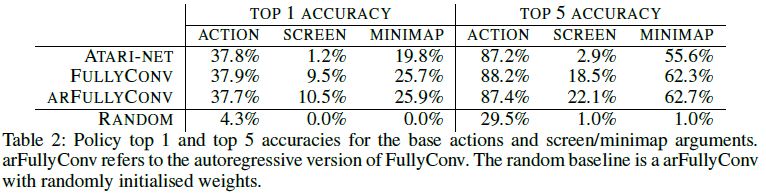
Table2는 어떻게 서로 다른 아키텍쳐가 행동 식별, 스크린, 미니맵과 같은 argument 예측의 정확도에 대해 수행하는지를 보여준다.
역시나, FullyConv 와 arFullyConv 아키텍쳐는 spatial argument에 대해 더 나은 수행결과를 보여준다.
또한 arFullyConv 아키텍쳐는 행동식별자가 이용된다는 것을 알고있으므로, FullyConv를 능가한다.
우리는 직접적으로 지도학습이 게임에서 학습되는 정책을 막는다.
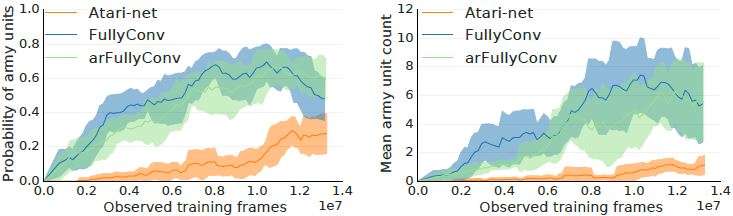
그것은 더 많은 유닛을 생산하고 관찰된 리플레이 데이터의 함수로써 더 잘 플레이했다.
Figure9와 영상 https://youtu.be/WEOzide5XFc을 참고하길 바란다.
그것은 또한 섹션4에서의 BuildMarines와 같은 행동 공간이 제한된 미니게임 뿐만 아니라
지도 정책에 제한이 없는 전체 1대1게임으로 학습된 모든 에이전트를 능가한다.
이러한 결과들은 supervised imitation learning은 스타크래프트2 에이전트의 부트스트랩에 대해 유망한 방향일지도 모른다.
향후 과제는 객관적으로 게임 결과와 같은 우리가 정말로 관심있는 부분에 대한 강화학습으로 직접 훈견된 imitation으로 초기화된 정책을 유념해야한다.
6 Conclusion & Future Work
이 논문은 심층 강화학습 연구에 대한 새로운 도전으로서의 스타크래프트2를 소개한다.
우리는 자유롭게 이용가능한 파이썬 인터페이스 뿐 아니라,
블라자드 공식 배틀넷 래더게임세서 랭크게임에서의 리플레이를 실제 유저의 리플레이를 제공한다.
이러한 초기 릴리즈에서 우리는 정책과 value network의 결과인 실제 유저 리플레이 데이터에 대한 지도학습 결과를 설명한다.
우리는 또한 간단하게 7가지 미니게임과 전체게임에 대해 베이스라인 RL에이전트를 말한다.
우리는 미니게임을 주로 유닛테스트로 여긴다.
즉, RL에이전트는 전체 게임에 대해 성공할때 실제 유저 레벨의 퍼포먼스가 용이해야한다.
그것은 추가적인 미니게임을 만드는데 유익할지도 모르지만,
우리는 최종 결과를 평가하는 전체게임을 가장 흥미로운 문제로 여기고,
다른 무엇보다도 이것을 해결하는 연구를 지향한다.
어떤 미니게임은 전문가 수주의 유저와 비슷한 수준을 보이는 반면,
우리의 기대대로, 현재 최신 베이스라인 에이전트는 초기 AI를 전체 게임에서 이길 수 없었다.
게임결과는 보상 시그널로 이용될 뿐만 아니라 보상의 구성하는 것은 각 타임스텝(즉, 블리자드에서 제공하는 네이티브 게임 스코어)에서 제공된다
이런 면에서 제공된 환경은 canonical하고, 외적으로 정의되었으며,
쉽게 뽑아 쓸수 있는 베이스라인 알고리즘에 대해 완전히 다루기 힘든 챌린징함을 나타낸다.
이번 릴리즈는 실제로 인간이 플레이하는 게임의 몇몇 면을 간략화 한다.
- 관측은 에이전트에 주어지기 전에 전처리 된다.
- 행동공간은 키보드와 마우스 클릭이 사용되는 실제 유저의 셋팅 대신 RL 에이전트에 의해 쉽게 사용된다.
- 실시간 대신, 각 시간 스템에 대해 에이전트가 계산할수 있는 최대한으로 lock-step으로 플레이 된다.
- AI를 상대하는 전체 게임만 허용한다.
그러나 우리는 에이전트가 RGB 픽센 관측과 제한된 시간 제한에서 최고의 실제 유저와 같은 플레이를 하는 에이전트를 개발하는 리얼 챌린지를 고려했다. 그러므로, 향후에는 셀프플레이가 가능하고, 트레이닝 에이전트의 목료로 움직이는 인간이 생각하는 공평한 적으로 인식되는 등, 위에서 설명한 간소화가 더욱 완화될 지도 모른다.