
분산 처리 시스템의 개념 이해(1)
업데이트:
분산 시스템의 개념(1)
참고링크
본 포스팅은 MIT 6.284 Distributed Systems을 참고하여 작성 되었습니다.
분산 시스템의 정의
분산 시스템(distributed systems)의 핵심은 여러개의 컴퓨터가 동일한 테스크를 처리하기 위해 네트워크상에서 서로 통신하며 협력하는 것입니다. 예를 들어, 거대한 웹사이트의 저장소라던가, 맵리듀스(MapReduce)와 같은 빅데이터 계산이라던가, peer-to-peer(P2P) 파일 공유 같은 것입니다. 요즘같은 시대에는 인프라 구조(infra structure)가 하나의 일(job)을 하기 위해 여러개의 컴퓨터가 필요한 시대입니다. 따라서 사람들은 이런 방법들을 연구하기 시작했어요. 여러분이 만약 하나의 컴퓨터를 사용해서 어떤 문제를 풀수있다면 분산 시스템을 구축할 필요는 없습니다. 실제로 하나의 컴퓨터로도 할수있는 일들이 정말 많죠. 분산시스템은 쉽지 않습니다. 따라서 여러분들은 하나의 컴퓨터로 작업을 끝낼수있도록 연구하는게 나을수도있습니다.
분산시스템을 구축하는 이유
high-performance
사람들이 분산시스템을 구축하는 이유는 여러개의 컴퓨터가 협력함으로써 high-performance를 보여줄 수 있는데요. 이를 위해서 parallelism이라는 게념이 필요합니다. 이는 많은 CPU, 많은 디스크, 메모리 등이 병렬로 연결된 것을 의미합니다.
fault tolerance
분산시스템을 구축하는 또 다른 이유는 단점을 견뎌낼수있기 때문입니다(tolerate faults). 두개의 컴퓨터가 같은 일을 할때, 그 중 한대가 실패했을때, 다른 한대로 커버 가능합니다.
Physical reason
서버가 물리적으로 떨어져있을때도 사용합니다. 예를들어, 은행 서버라고 했을 때, 한대는 뉴욕에 배치하고, 다른 하나는 런던에 배치할 수도 있죠.
security
보안상의 문제가 있을 때 서로다른 권한, 프로토콜에 따라 다르게 배치할 수 있습니다. 즉 고립된(isolated) 컴퓨터를 따로 구성할 수 있습니다.
분산 시스템이 어려운 이유
굉장히 많은 파트가 있고, 그것들이 동시에 실행됩니다. 따라서 어떤 문제가 발생했을 때, 컴퓨터간에 복잡하게 연결되어있는 부분이 있을 것이고, 시간에 의존적인(timing dependent stuff) 것도 있을 것입니다. 분산 시스템이 어려운 또다른 이유는 분산시스템에는 굉장히 많은 파트와 네트워크가 있는데, 여러분은 예상치못한 실패를 굉장히 많이 겪게 됩니다. 하나의 컴퓨터로 할 때는 잘 실행되건 것이, 분산 시스템에서는 크래쉬가 발생하거나 알 수 없는 이유로 실패할 수 있습니다. 여러분은 분산 시스템의 수많은 컴퓨터 중에 네트워크상 문제로 어떤 파트가 성공하고, 어떤 파트는 실패할 수 있습니다. 이러한 부분적 실패(partial failure)가 분산 시스템이 어려운 또다른 이유 입니다. (challenges concurrency partial failure) 분산 시스템이 어려운 또다른 이유는 1000대의 컴퓨터를 사용한다고해서 1000배의 성능향샹이 따라오는 것은 아니기 때문입니다.(performance문제) 분산시스템은 현실에서 많은 분야에 쓰입니다. 예전에는 하나의 개인컴퓨터로도 웹사이트를 만드는고 운영하는데 문제없었지만, 웹사이트가 점점 커지고 엄청나게 많은 데이터를 저장하고 다루기 위해 연구한 끝에 분산시스템은 요즘 시대에 매우 중요한 인프라구조가 되었습니다. 분산시스템에 관해서 많은 부분이 해결된 부분도 있지만 해결되지 않은, 연구가 필요한 부분도 아직 많습니다. 만약 여러분이 분산시스템을 구축하고 싶다면 이 수업은 좋은 수업이 될 것입니다.
이 포스팅 시리즈에서 다룰 것
분산시스템을 실현(implementation)하기 위해 필요한 것들
- Remote Procedure Call(RPC)
- 쓰레드(Threads)
- Concurrency Control
성능(performance)
- 확장성(Scalability)
일반적으로 분산시스템의 높은목표(high-level goal)는 scalable spped-up 입니다. 구체적으로 확장성이 뭐냐면, 어떤 문제를 풀기 위해 하나의 컴퓨터로 한 시간이 걸린다고 합시다. 만약 제가 두번째 컴퓨터를 산다면 문제를 푸는 시간이 절반으로 줄어들어 30분만에 풀게 될거라고 기대하죠.
2$\times$computers -> 2$\times$throughput
이 방법이 꽤 싸게먹히는 것이, 문제를 풀기 위해 단지 컴퓨터만 더 사면 된다는 것입니다. 만약 컴퓨터를 더 사지 않고 문제를 해결하려면 더 능력있는 프로그래머를 고용하거나 해야죠.
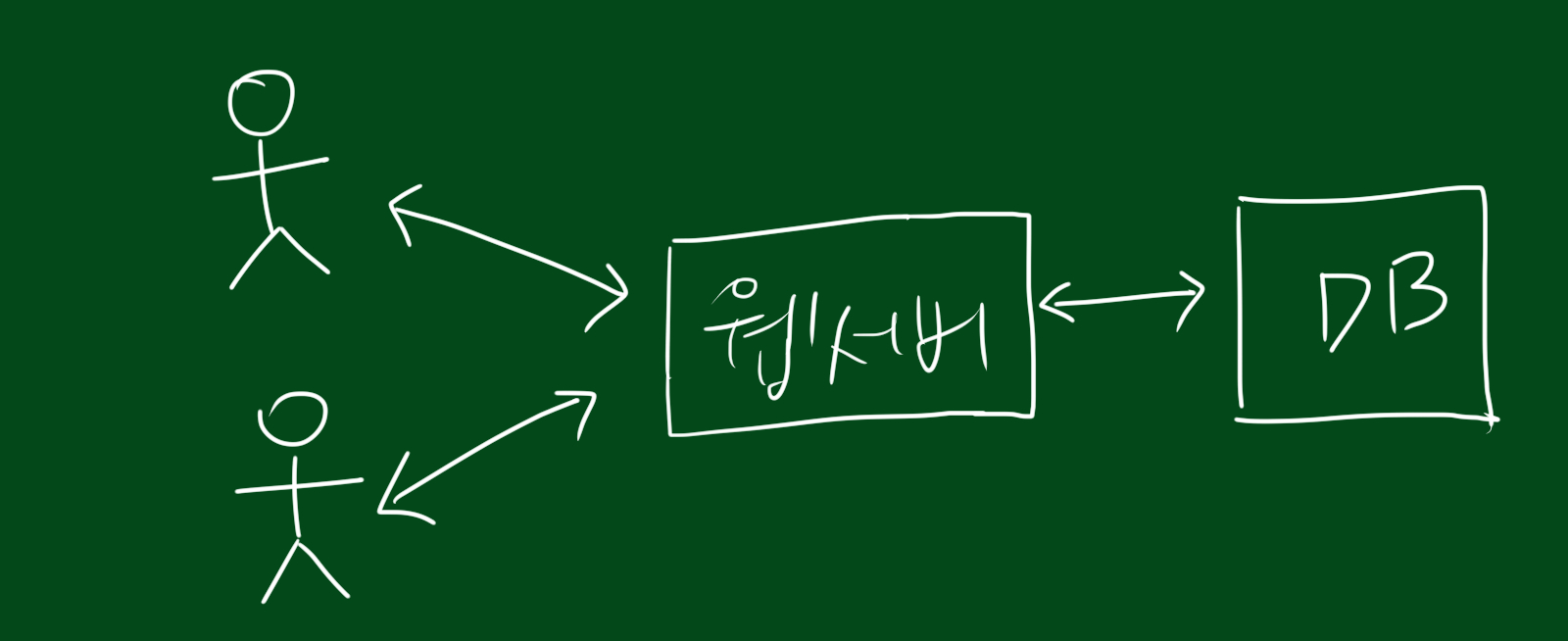
한두명이 웹서버에 접근할 때는 하나의 컴퓨터로 충분합니다. 하지만 몇백만명이 접속할때는 어떻게 해야할까요? 단순히는 웹서버를 늘리고, 유저를 각각 다른 웹서버에 접속하게끔 아래그림처럼 쪼개면 됩니다.
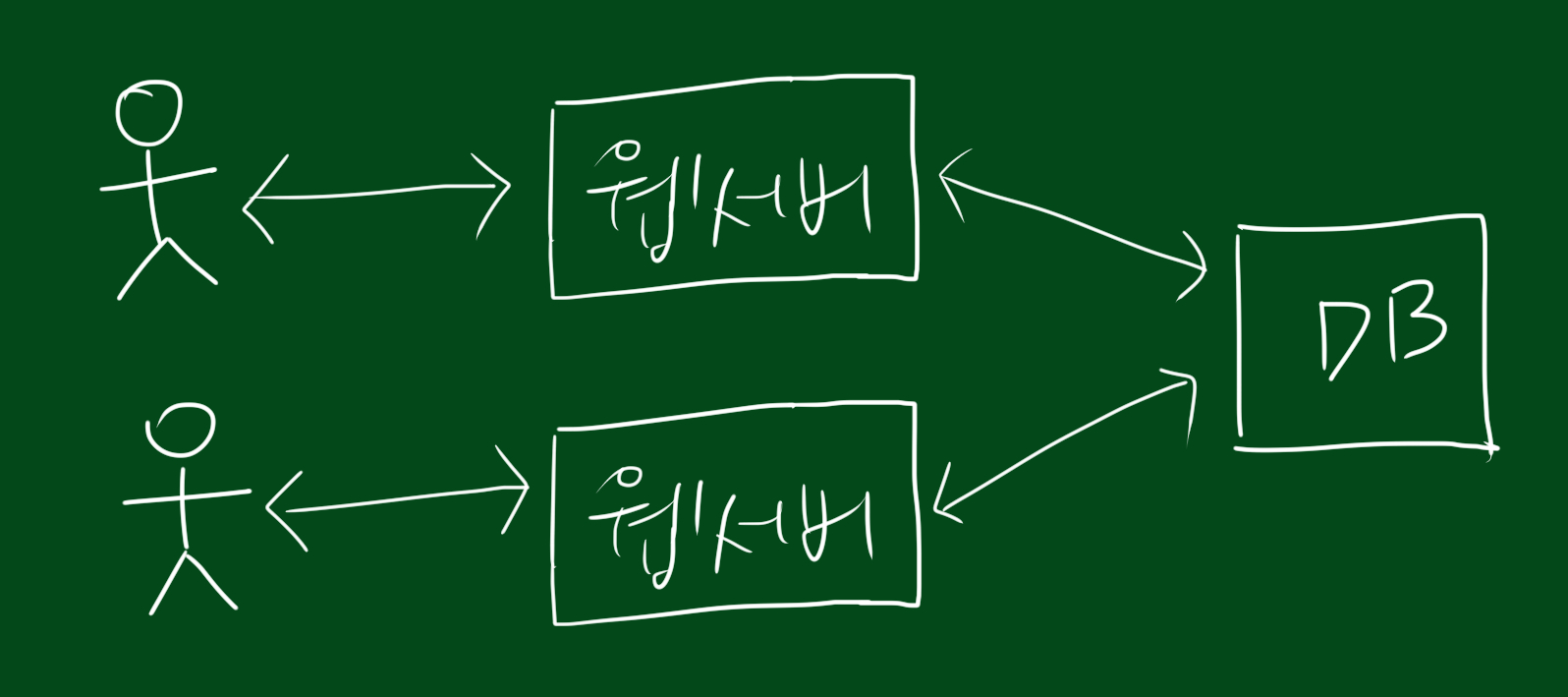
물론 사용자는 같은 화면을 봐야하기 때문에 웹서버는 같은 DB를 바라봐야합니다. 하지만 위와 같은 시스템에서 웹서버를 무한정 늘리다가는 웹서버가 데이터베이스의 데이터를 읽는 과정에서 병목이 생깁니다. 따라서 DB도 함께 늘려줘야하죠.
Fault Tolerance
보통 컴퓨터 한대로 서버를 구성할 경우 크래쉬 없이 1년 정도 버팁니다. 하지만 여러분이 1000대의 컴퓨터로 분산처리할 경우 하루에 3,4대 정도 고장이납니다. 즉, 매일 어떤 컴퓨터는 고장난다는 뜻이죠. 크래쉬가 나거나, 알수없는 오류, 혹은 느려지거나 하는 등의 이유로 말입니다. 각 시스템은 엄청나게 많은 네트워크 케이블과 스위치로 연결되어 있죠. 케이블 연결이 잘못되어있거나, 스위치를 식혀주는 fan이 고장나서 열받았다거나 여러가지 문제가 발생할 수 있습니다.
Availability
전체 시스템에서 일부 시스템이 고장나더라도 서비스가 멈춰서는 안됩니다. 복제된 서버들을 놓고 설령 하나가 고장나더라도 다른 서버가 역할을 대신 해주어야합니다.
Recoverability
만약 뭔가 잘못되어서 서비스가 멈추더라도 복구된 이후에 중단되었던 요소(component)가 계속되어야합니다. 디스크가 최신으로 유지되어야하죠.
위 두가지 목표를 위해 중요한 것이 비휘발성 저장공간(Non-volatile storage), 복제(Replication)입니다.
Consistency
저장소에 키값 쌍을 저장한다고 합시다. 즉, Put(k, v)라고 하죠. 그럼 사용자가 키를 통해 값을 얻을 수 있는데요. 이를 get(k) -> v 라고 합시다. 기본적으로 키값 서비스(key-value service)는 매우 유용합니다.
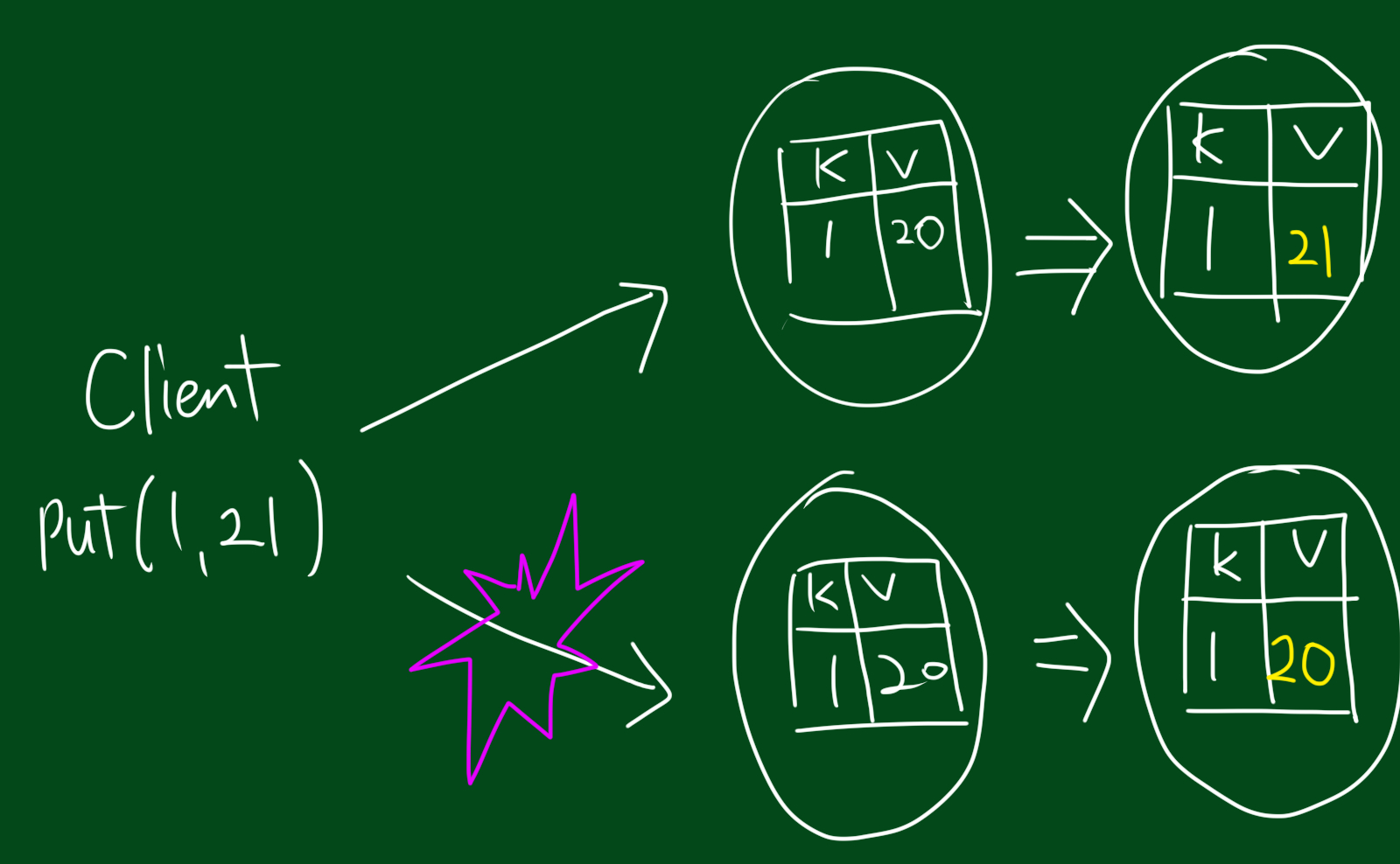
위 그림을 봅시다. 만약 두 대의 서버가 있고 각각 키값테이블이 있다고 합시다. 이때 키는 1이고 값은 20입니다. 그런데 사용자가 키값을 (1,20)에서 (1,21)로 바꾸고 싶어합니다. 당연히 서버 두대 모두 변경해야하는데요. 만약 사용자로부터 서버1로가는 요청은 성공했는데 서버2로가는 요청이 잘못된다면 서버2의 키값은 갱신되지 않습니다. 이런 상황에서 만약 서버1이 돌아가다 멈춰서 서버2로 대체된다면 어떻게 될까요? 키값의 일관성이 없어질 것입니다. 이런 상황을 consistency 하지 않다고 합니다. 반대로 strong consistency하다는 말은 가장 최신 데이터를 볼수있는 것을 보장한다는 뜻이고 weak consistency하다는 말은 최신 데이터를 볼수있다는 보장을 할 수 없다는 것을 의미합니다. 또한 strong consistency를 유지하는건 비용이 많이 듭니다. 이것이 힘든 이유는 서버가 아주 멀리 떨어져있다고 해봅시다. 하나는 아시아에 있고 하나는 아메리카에 있는데, 어느 한곳에 지진이나서 고장이난다고 해봅시다. 이런 경우에 전파가 이동하는 속도는 아주짧은데, 이런 상황에서 strong consistency를 유지하는건 아주 많은 비용이 들죠
맵리듀스(MapReduce)
맵리듀스는 구글이 2004년에 디자인한 시스템입니다. 그들은 테라바이트의 엄청난 크기의 데이터로 계산을 했어야했는데요. 웹사이트 전체에서 가장 중요한 페이지가 무엇인지 계산을 위해 모든 웹사이트 내용에 대해 인덱스를 만들었습니다. 웹에 대해 인덱스를 만든다는 것의 의미는 모든 데이터를 정렬시키는 것과 동일합니다. 이걸 컴퓨터 단한대로 한다고 가정해봅시다. 몇일, 몇달 몇년이 걸릴지도 모릅니다. 엔지니어들은 그걸 그냥 기다릴수는 없었죠. 그래서 탄생한 것이 맵리듀스입니다.
맵리듀스 개념
맵리듀스는 프레임워크입니다. 각각의 인풋파일에 대해서 map function이 적용되는데요. 아웃풋은 키값쌍이 됩니다. 쉽게 글자수를 세는 것에 대한 예를 들어봅시다. 그러면 맵함수의 결과는 (단어, 1) 형태가 될건데요. 맵리듀스 프레임워크의 중요한 개념은 모든 map으로부터의 인스턴스를 한데 모으는 것입니다. 아래 그림을 보시면 이해가 빠르실 겁니다. 이것이 MapReduce Job 입니다. 이때 input파일 하나에 대해 처리하는걸 task라고 하고 아래그림처럼 맵리듀스 전체를 Job이라고 합니다.
