
[python] 파이썬 판다스(pandas) loc, iloc 차이
업데이트:
파이썬 판다스(pandas) loc, iloc 차이
판다스에서 데이터프레임을 특정 행, 열을 기준으로 나누고 싶을 때, loc, iloc을 주로 사용합니다. 이 둘의 차이는 loc은 ‘변수명’을 기준으로 데이터프레임을 분리하고, iloc은 ‘인덱스번호’로 분류합니다.
1. 사전준비
먼저 데이터프레임을 다루기 위한 판다스(pandas)와 데이터셋 사용을 위한 사이킷런(sklearn) 라이브러리를 불러옵니다.
import numpy as np
import pandas as pd
from sklearn import datasets
라이브러리를 불러왔으면 보스톤 집값 데이터를 불러와서 판다스를 이용해 데이터프레임으로 만듭니다.
raw_boston = datasets.load_boston()
raw_boston_data = pd.DataFrame(raw_boston.data)
raw_boston_target = pd.DataFrame(raw_boston.target)
rawdata_boston = pd.concat([raw_boston_data,raw_boston_target], axis=1)
column_total_boston=np.append(raw_boston.feature_names, ['target'])
rawdata_boston.columns = column_total_boston
rawdata_boston

2. loc: 변수명을 사용해서 데이터프레임 분리하기
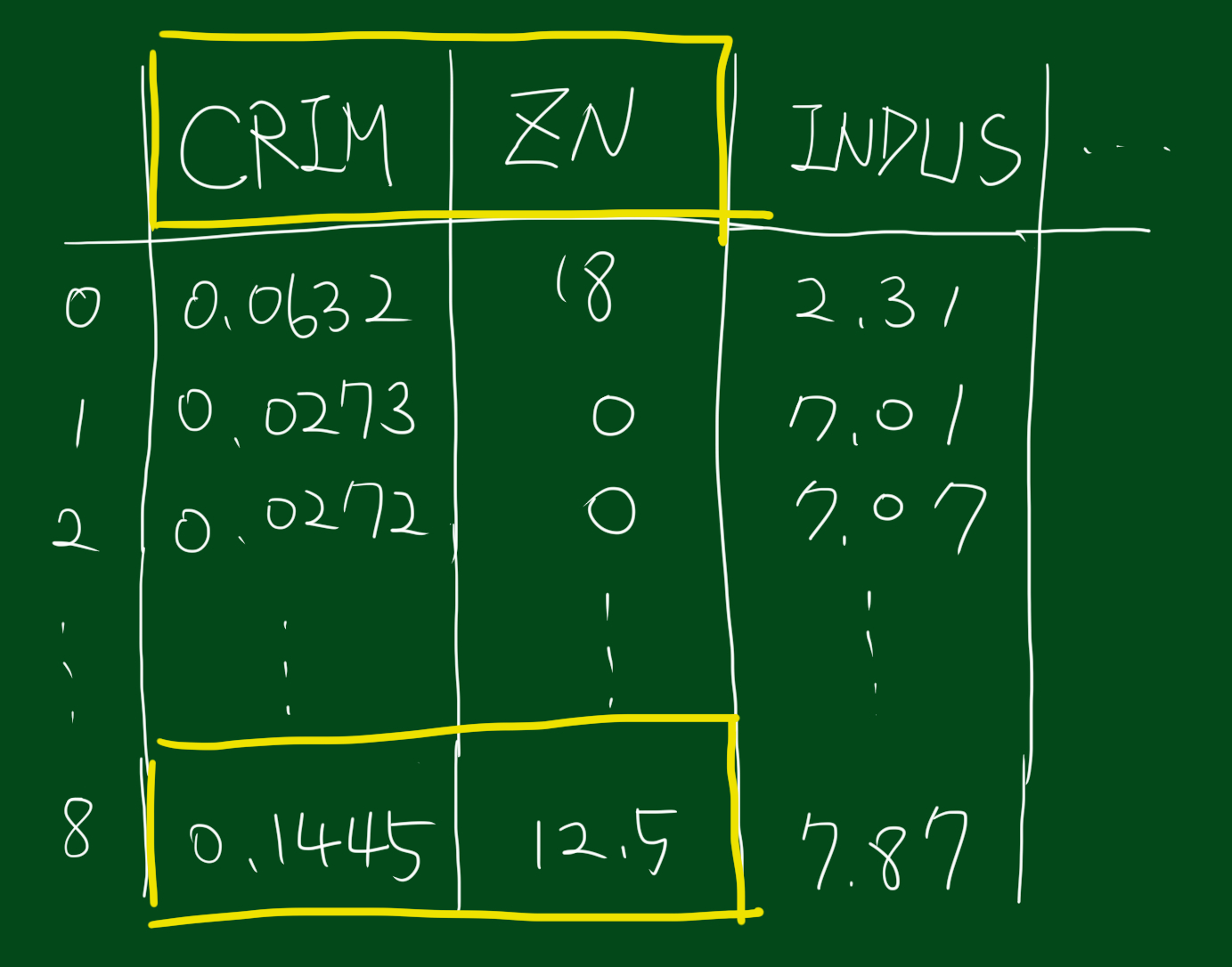
‘CRIM’, ‘ZN’ 열만 가져오기
열이름(column name)은 대소문자 영향을 받으므로 정확히 입력하셔야합니다.
rawdata_boston.loc[:,['CRIM','ZN']]
위 코드르 입력하시면 전체 데이터프레임에서 ‘CRIM’, ‘ZN’열만 가져옵니다. 이번에는 행에도 조건을 걸어서 가져와보겠습니다.

rawdata_boston.loc[rawdata_boston['CRIM']>0.3,['CRIM','ZN']]
위 코드는 ‘CRIM’, ‘ZN’열만 가져오는데 ‘CRIM’컬럼값이 0.3보다 큰 행만 가져옵니다.
3. iloc: 인덱스 번호를 사용해 데이터프레임 분리하기
위와 같이 ‘CRIM’, ‘ZN’열만 가져오는데 열 이름으 사용하는 대시 열번호로 가져와 보겠습니다. 파이썬은 0부터 시작하므로 0번째열인 ‘CRIM’과 1번쨰열인 ‘ZN’만 가져오는 코드는 아래와 같습니다.
rawdata_boston.iloc[:,[0,1]]
이번에도 행조건을 넣어보겠습니다.
rawdata_boston.iloc[rawdata_boston['CRIM']>0.3,[0,1]]
NotImplementedError: iLocation based boolean indexing on an integer type is not available
loc을 사용할때와는 다르게 입력이 iloc에서는 boolean을 포함하는 조건을 넣을 수 없습니다. 따라서 boolean 조건을 넣고 싶다면 iloc이 아닌 loc을 사용하셔야겠습니다.