
[python] 파이썬 웹 크롤링(2): 데이터 파싱
업데이트:
파이썬 웹 크롤링(2): HTML 파싱
본 포스팅은 Web Scraping with Python by Ryan Mitchell을 참고하였습니다.
참고 링크
- 파이썬 웹 크롤링(1): 크롤링의 기본구조와 BeautifulSoup 설치
- 파이썬 웹 크롤링(2): 데이터 파싱하기
- 파이썬 웹 크롤링(3): 본격적인 크롤링
- 파이썬 웹 크롤링(4): API 활용하기
- 파이썬 웹 크롤링(5): 데이터 저장하기
- 파이썬 웹 크롤링(6): 데이터 읽기
Chapter2: HTML 파싱
2.1 BeautifulSoup의 또다른 기능
Chapter 1에서는 BeautifulSoup을 설치하고 HTML 내용을 읽어들이는 방법을 알아보았습니다. 이번 챕터에서는 속성(attribute)를 기반을 태그(tag)를 찾아보고 트리 형식으로 되어있는 태그를 탐험해보겠습니다.
여러분은 거의 모든 웹사이트에서 스타일시트(stylesheet)를 보게될 것입니다. 브라우저의 종류에 따라 디자인된 웹사이트의 스타일 레이어가 별로 안좋다고 생각할 지라도, CSS의 출현은 크롤링에는 좋은 현상이었습니다. CSS는 그들이 표현하고자하는게 다를지라도 같은 마크업을 사용하는 HTML 요소의 차별성에 의존합니다. 예를 들어 아래와 같은 태그가 존재할 때
<span class="green"></span>
다른 것은 아래와 같습니다.
<span class="red"></span>
웹 크롤러는 클래스(class)에 기반한 서로다른 두 태그를 쉽게 구분할 수 있습니다. 예를 들어, BautifulSoup을 사용해서 모든 빨간 텍스트(red text)를 잡아내고 초록색 텍스트(green text)는 걸러낼 수 있습니다. 왜냐하면 CSS는 웹사이트의 속성(attribute) 식별에 의존하고, 클래스와 ID 속성은 거의 모든 웹사이트에 존재합니다.
아래와 같은 웹사이트를 크롤링한다고 해봅시다.
http://www.pythonscraping.com/pages/warandpeace.html
위 사이트에서 주인공의 대사는 빨강색으로 처리되어있는 반면 캐릭터 이름은 초록색으로 처리되어 있습니다. 여러분은 CSS 클래스 내부의 span 태그를 이용해 볼 수 있습니다. 다음은 페이지 소스의 일부입니다. (여러분이 직접 보고 싶다면 위 사이트를 접속해서 F12를 눌러서 확인할 수도 있습니다.)
"<span class="red">Heavens! what a virulent attack!</span>" replied <span class=
"green">the prince</span>, not in the least disconcerted by this reception.
일단 차근차근 진행해보겠습니다. 챕터 1에서 했던 것 처럼 BeautifulSoup을 이용해 페이지 전체를 긁어와 보겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html)
BeautifulSoup을 이용해 만든 bsObj 오브젝트 파일을 이용해 findAll 함수를 이용해 적절한 명사 리스트를 추출할 수 있습니다.
>>> nameList = bsObj.findAll("span", {"class":"green"})
>>> for name in nameList:
>>> print(name.get_text())
Anna
Pavlovna Scherer
Empress Marya
Fedorovna
...중략
위 코드를 실행하니 뭔가 나오긴 나옵니다. findAll 함수의 사용법은 아래와 같습니다.
bsObj.findAll(tagName, tagAttributes)
즉 해당 태그 tagName과 tagAttributes에 해당되는 데이터를 가져옵니다. findAll은 페이지 전체에 존재하는 모든 tagName 데이터를 가져옵니다. 반면 bsObj.tagName은 가장 처음 나오는 tagName에 해당하는 데이터를 가져옵니다. 위 코드에서 name 자체를 출력하면 아래와 같습니다.
>>> print(nameList)
[<span class="green">Anna
Pavlovna Scherer</span>, <span class="green">Empress Marya
Fedorovna</span>, <span class="green">
...중략
따라서 name.get_text()는 태그 내부의 내용물만 보고 싶을 때 사용합니다.
2.2 find(), findAll()
find() 함수와 findAll() 함수는 여러분이 크롤링할 때 아마 가장 많이 사용하는 함수가 될 것입니다. 이 두 개의 함수를 사용하면 HTML 내용을 필터링하고 원하는 태그를 찾는 데 유용합니다. 게다가 이들을 사용하는 방법은 매우 간단합니다.
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
find() 함수와 findAll() 함수의 사용법은 위와 같습니다. 다양한 옵션들을 사용할 수 있지만 여러분이 실제로 사용할 때는 95%의 확률로 tag, attributes 단 두개의 옵션만 사용할 것입니다. 하나하나 옵션들을 살펴봅시다.
2.2.1 tag
tag 인자는 이전 챕터에서 이미 보았습니다. 여러분은 tag 인자값으로 태그이름을 하나 넣거나 태그 이름을 여러개 넣은 리스트를 넣을 수도 있습니다. 예를 들면 아래와 같습니다.
.findAll({"h1","h2","h3","h4","h5","h6"})
2.2.2 attributes
attributes 인자는 파이썬에서 딕셔너리 형식을 취합니다. 예를 들어 아래 코드는 HTML내부의 초록색과 빨간색 span 태그를 가져옵니다.
.findAll("span", {"class":"green", "class":"red"})
나머지 인자들은 미리 공부를 한다기보다 필요할 때 찾아보는게 효율적일 것입니다.
2.3 Tree 구조 탐험하기
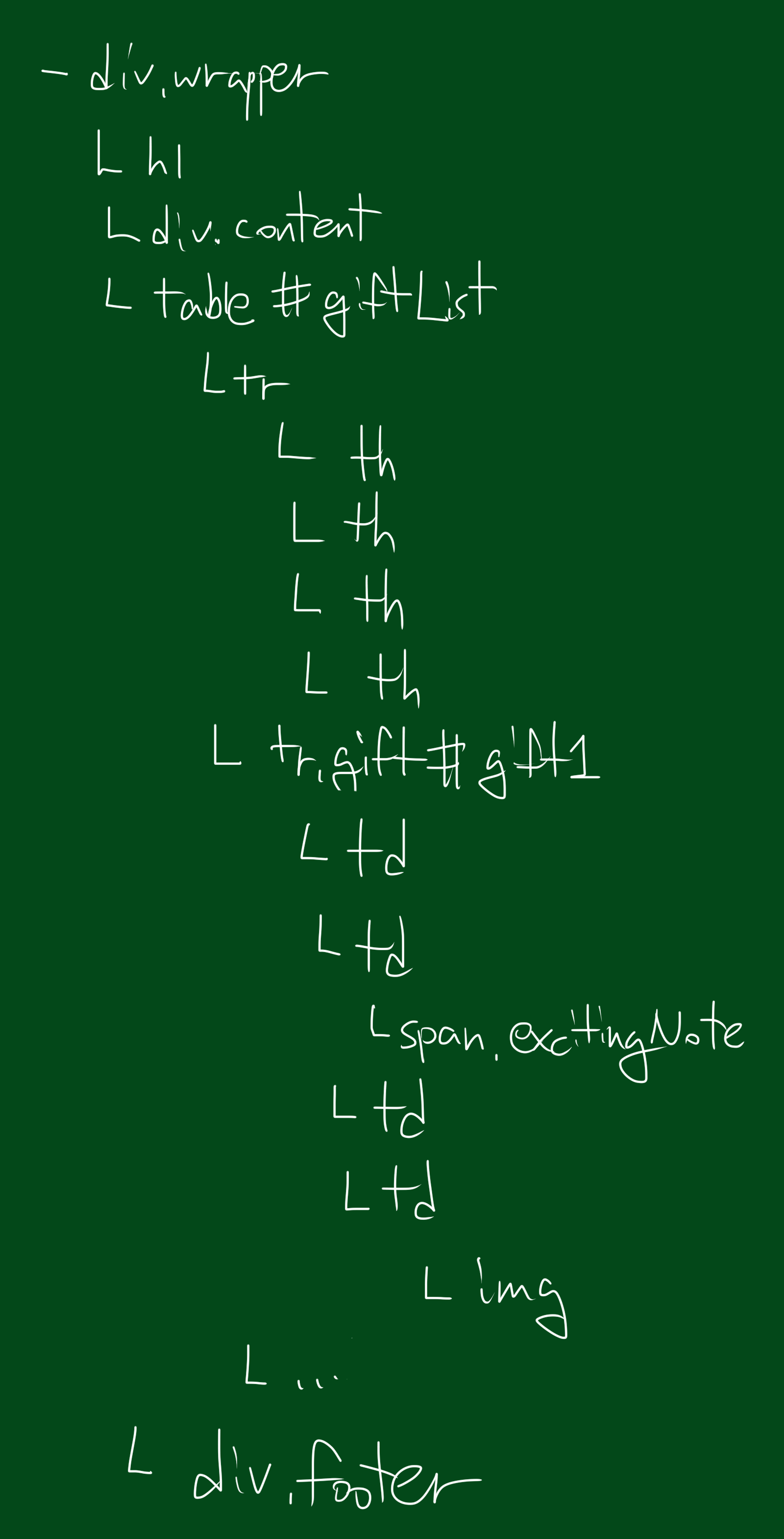
2.3.1 자식(children), 후손(descendant) 다루기
크로링에서 언급하는 자식(children)의 개념은 컴퓨터 공학에서 흔히 말하는 자식 프로세스와는 조금 다릅니다. BeautifulSoup 라이브러리를 포함한 많은 라이브러리는 자식(children)과 후손(descendant)을 다르게 구분합니다. 자식(children)은 항상 부모(parent)의 딱 한 단계 하위의 태그를 말하는 반면(부모 바로 밑), 후손(descendant)은 부모보다 아래기만 하면 어떤 레벨에 존재해도 상관 없습니다.
일반적으로 BeautifulSoup은 항상 현재 선택된 태그의 후손을 다룹니다. 예를 들어, bsObj.body.h1은 첫번째 h1 태그를 선택하는데, 이는 body 태그의 후손을 의미합니다. 이 경우, body 밖의 tag는 찾지 않습니다.
이와 비슷하게, bsObj.div.findAll(“img”)는 문서 내 첫번째 div 태그를 찾습니다. 그리고 나서 모든 img 태그의 리스트를 찾아옵니다. 이 때 img 태그는 div 태그의 후손입니다.
만약 여러분이 오직 자식에 해당하는 후손만 찾고 싶다면 .children 을 사용합니다.
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> html = urlopen("http://www.pythonscraping.com/pages/page3.html")
>>> bsObj = BeautifulSoup(html)
>>> for child in bsObj.find("table",{"id":"giftList"}).children:
>>> print(child)
<tr><th>
Item Title
</th><th>
Description
</th><th>
Cost
...중략
위 코드는 giftList 테이블 내부의 상품 행 리스트를 출력합니다. 만약 children() 대신 descendants() 함수를 사용한다면, 테이블 내부의 20여개의 태그를 찾게 될 것입니다. 이는 img 태그, span 태그, 그리고 각각의 td 태그들을 포함합니다!
자식과 후손을 구분하는 것은 매우 중요합니다.
2.3.2 형제(sibling) 다루기
BeautifulSoup의 next_siblings() 함수를 사용하면 테이블로 부터 데이터를 모을 수 있는데,
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
위 코드의 아웃풋은 첫번째 타이틀 행을 제외한, 상품 정포 테이블의 모든 상품의 행을 의미합니다. 타이틀 행은 왜 제외했을까요? 이는 두가지 이유가 있습니다. 첫째, 오브젝트는 그들 자신과 형제가 될 수 없습니다. 여러분이 어떤 오브젝트의 형제를 얻을 때, 오브젝트 그 자체는 리스트에 포함되지 않습니다. 둘째, 이 함수는 오직 next 형제를 호출합니다. 만약 여러분이 리스트 중간 행을 선택하고 next_siblings를 실행하면 그 다음(next) 형제가 선택될 것입니다. 그래서 타이틀 행을 선택하고 next_siblings를 실행하면, 타이틀 행 그 자체를 제외한 테이블 내 모든 행을 선택할 수 있는 것입니다.
next_siblings과 유사하게 previous_siblings을 사용하면 이전 형제를 선택할 수 있습니다. 그리고 s를 제외한 next_sibling과 previous_sibling 도 존재합니다. 이들은 리스트 전체를 가져오는 것이 아니라 단 하나의 태그만 가져온다는 차이점이 있습니다.
2.3.2 부모(parents) 다루기
크롤링 할 때 여러분은 태그의 자식을 찾는 일보다 부모를 찾는 일은 덜 발생할 것입니다. 일반적으로 우리가 HTML 페이지를 볼 떄 크롤링의 목적은 top 태그로부터 시작해서 얼마나 깊게 파고 드냐의 문제입니다. 하지만 가끔 부모를 찾을 일도 있는데요. 이 때 .parent와 .parents를 사용합니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"
}).parent.previous_sibling.get_text())
위 코드는 ../img/gifts/img1.jpg 위치에 존재하는 이미지의 가격을 출력합니다. ($15.00) 이것은 어떻게 가능할까요?
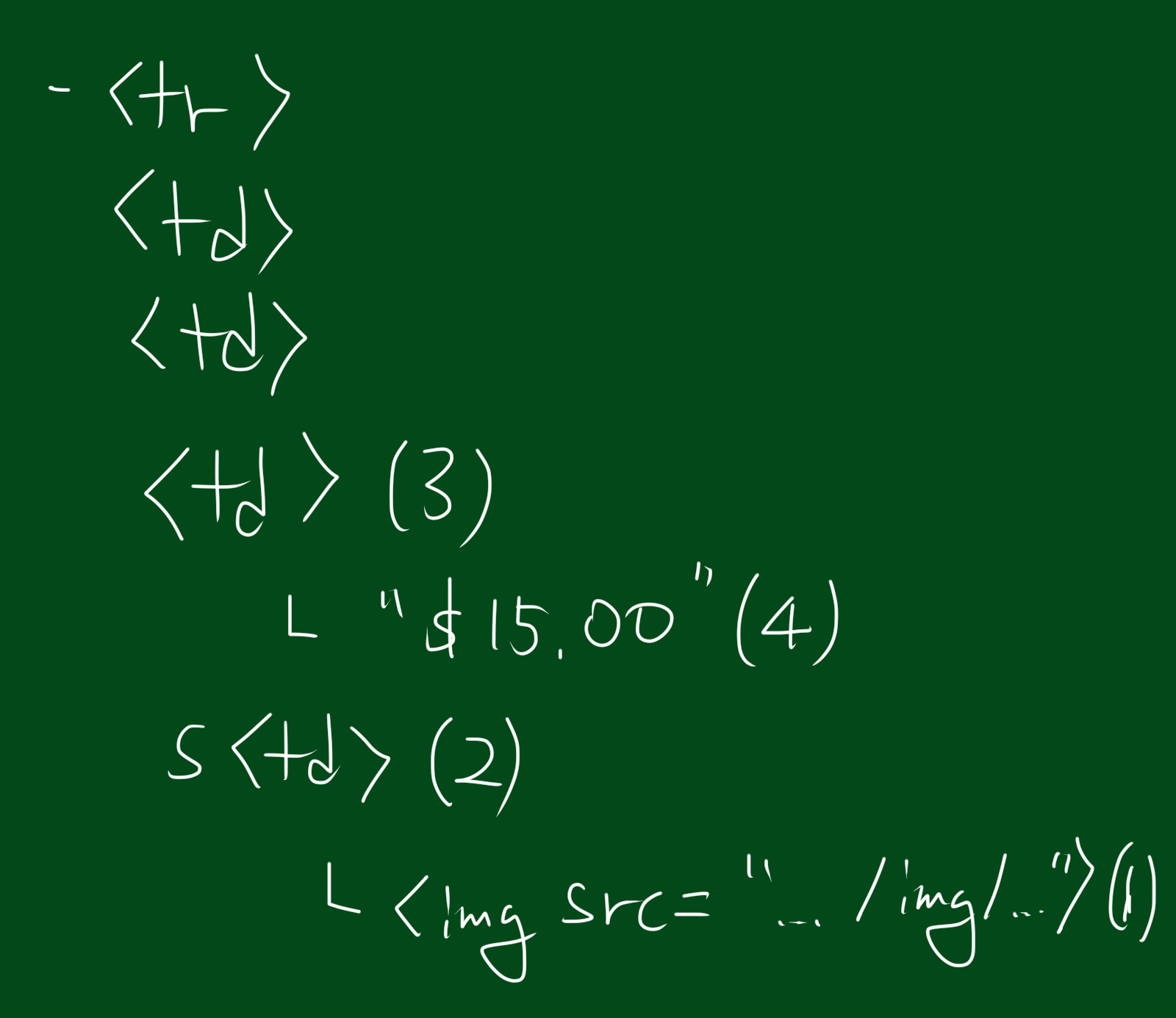
-
이미지 태그 src=”../img/gifts/img1.jpg” 를 선택한다
-
부모 태그 <td> 를 선택한다
-
태그의 형제를 선택하기 위해 previous_sibling를 실행한다. - $15.00 이라는 텍스트를 선택한다.
2.4 정규표현식
크롤링을 할 때는 정규식(정규표현식)을 사용할 줄 알면 좋습니다. 정규식은 검색을 용이하게 해주는 표현식인데, 정규식에 대해서는 나중에 따로 포스팅 하겠습니다.
2.5 속성에 접근하기
지금까지 사이트에 어떻게 접근하고 어떻게 태그를 필터링하고 어떻게 내용물에 접근하는지 배웠습니다.
하지만 우리가 찾는 것은 태그 속 내용에 없는 경우가 많습니다.
태그가 아니라 속성(attribute)를 찾아야할 때가 많습니다.
이들은 태그를 와 같이 검색할 때 우용합니다.
예를 들어 우리가 찾는 내부 URL이 href 속성에 첨부되어 있거나,
혹은 이미지 파일을 찾는데 태그 내부에 있는 것이 아니라 src 속성내부에 있는 경우 입니다.
태그 내부의 속성에 접근하려면 아래와 같은 문법을 사용합니다.
myTag.attrs
위 코드의 결과는 딕셔너리 오브젝트를 보여줍니다. 따라서 이미지 위치를 찾기위해서는 아래와 같은 방법을 사용합니다.
myImgTag.attrs['src']