
[머신러닝] 크로스 밸리데이션(cross validation, 교차 검증)의 개념, 의미
업데이트:
[머신러닝] 크로스 밸리데이션(cross validation, 교차 검증)의 개념, 의미
참고링크

오늘은 크로스 밸리데이션(cross validation)의 의미를 알아보겠습니다. 크로스 밸리데이션은 우리말로 ‘교차 검증’이라고도 합니다. 흔히 트레이닝 셋(training set), 밸리데이션 셋(validation set), 테스트 셋(test set)이라는 단어를 많이 사용하는데, 오늘은 이것들과 관련된 내용을 다루려고 합니다.

위와 같은 데이터가 있다고 생각해봅시다. 목표는 우리에게 주어진 저 데이터를 이용해 목적에 맞는 적절한 모형을 만드는 .

자, 모형을 만들어야하므로 학습시킬 데이터가 필요하겠네요. 그러면 데이터 전체를 트레이닝 셋으로 사용해볼까요? 위 그림처럼 데이터 전체를 트레이닝 셋으로 학습시키면 머신러닝 모형을 만들수 있습니다. 하지만 여기서 한가지 문제점이 발생합니다. 모형은 만들어냈지만, 모형의 성능을 평가할 수 없습니다. 즉, 생성된 모형이 좋은지 안좋은지 알 수 없다는 거죠. 왜 평가를 할 수 없을까요? 트레이닝 셋을 넣고 평가하면 안될까요? 네, 안됩니다. 왜냐하면 우리가 만든 모형은 트레이닝 셋을 기반으로 만들었으므로 평가할 때 트레이닝 셋을 사용하면 당연히 결과가 좋을 수 밖에 없습니다. 예를 들어, 우리가 시험보기 전에 기출문제로 공부했는데, 실제 시험문제를 기출문제와 동일하게 하면 당연히 결과는 100점이겠죠? 그래서 평가를 위한 새로운 데이터가 필요합니다. 하지만 새로운 데이터를 구한다는 것은 아주 어려운 일입니다. 따라서 우리는 기존 데이터를 두 부분으로 나누어서 사용하기로 합니다.
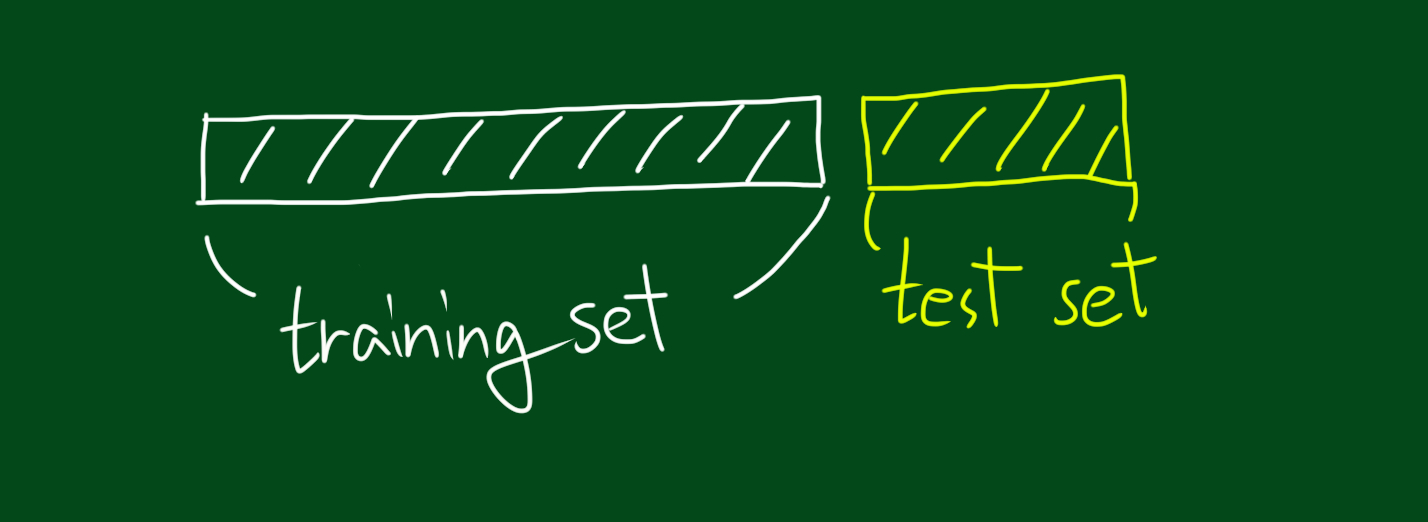
모델의 성능 평가를 위해 데이터를 두 부분으로 나눕니다. 위 그림처럼 학습을 위한 부분을 트레이닝 셋이라고 하고, 평가를 위한 부분을 테스트 셋이라고 합니다. 머신러닝 모형을 학습 시킬 때는 오직 트레이닝 셋만 사용합니다. (이 때는 테스트셋은 사용하면 안됩니다.) 그리고 모형 학습이 끝났다면 테스트 셋으로 평가를 합니다. 이제 문제가 해결된것 같네요.
하지만 여기서 또 문제점이 발생할수 있는 상황이 존재합니다.
그것은 바로 하이퍼파라미터(hyperparameter)를 정해야할때 인데요.
기존 데이터를 트레이닝 셋과 테스트 셋으로 나누기만 할 경우,
평가를 위해 사용해야할 테스트 셋이 하이퍼파라미터 적합에 사용됩니다.
즉, 하이퍼파라미터가 테스트 셋에 영향을 받는다는 것이죠.
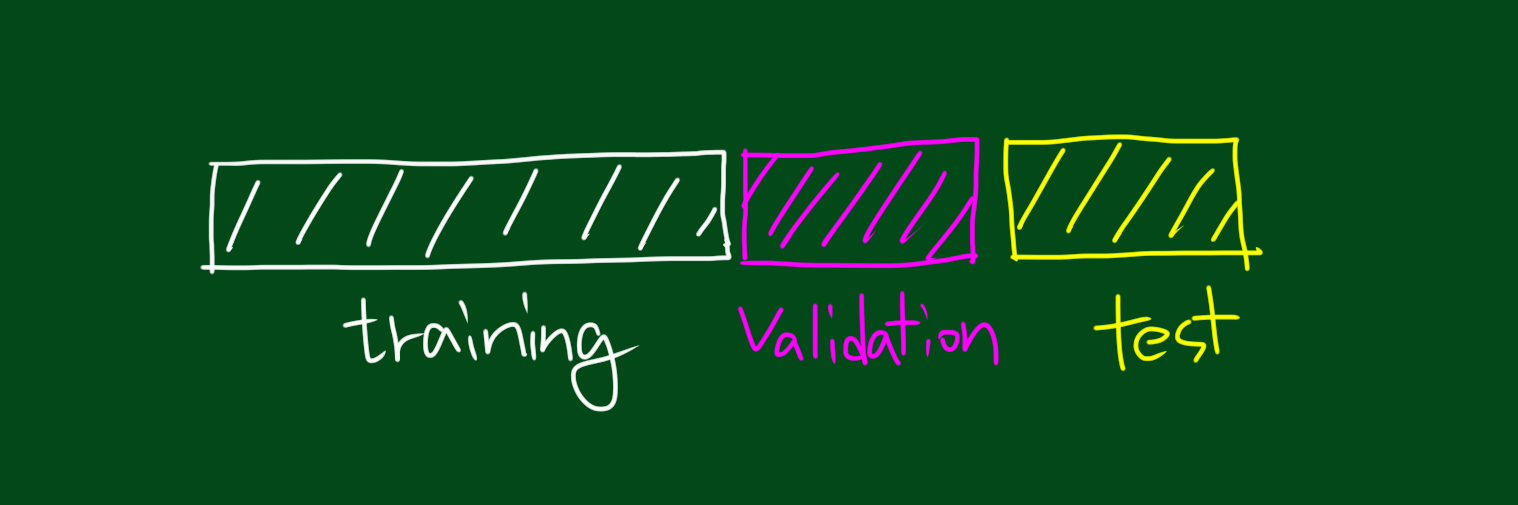
그래서 밸리데이션 셋(validation set)이 필요한 것입니다.
모형의 파라미터 추정에는 트레이닝셋을 사용하고,
하이퍼파라미터 설정에는 밸리데이션 셋을 사용합니다.
그리고 마지막으로 테스트 셋에 모형을 적용시켜 정확도를 측정합니다.
즉, 트레이닝 셋으로 학습시키고, 밸리데이션 셋으로 하이퍼파라미터 튜닝하고, 테스트 셋으로 최종 테스트를 하는 것입니다.
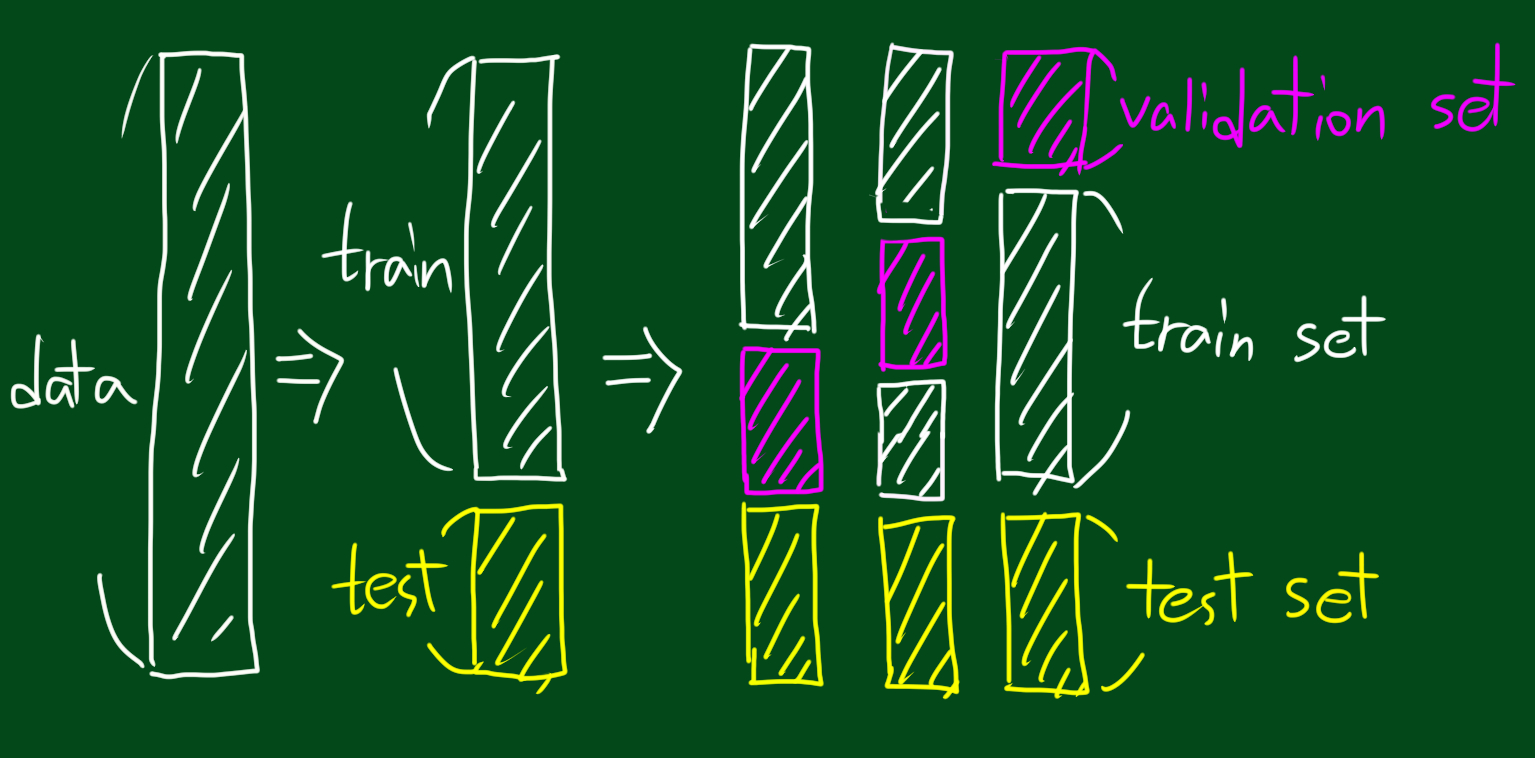
그리고 트레이닝을 k등분하고 validation set을 여러번 바꿔가며 반복적으로 시행하는 방법을 k-fold cross validation이라고 합니다. 위 그림에서는 3등분했으니 3-fold cross validation이겠네요. 물론 꼭 저렇게 해야한다는 것은 아니고 전체 데이터를 k등분한 후 밸리데이션 셋 없이 테스트 셋 위치를 바꿔가며 테스트 하는 방법 등 여러가지 응용 방법이 존재합니다.
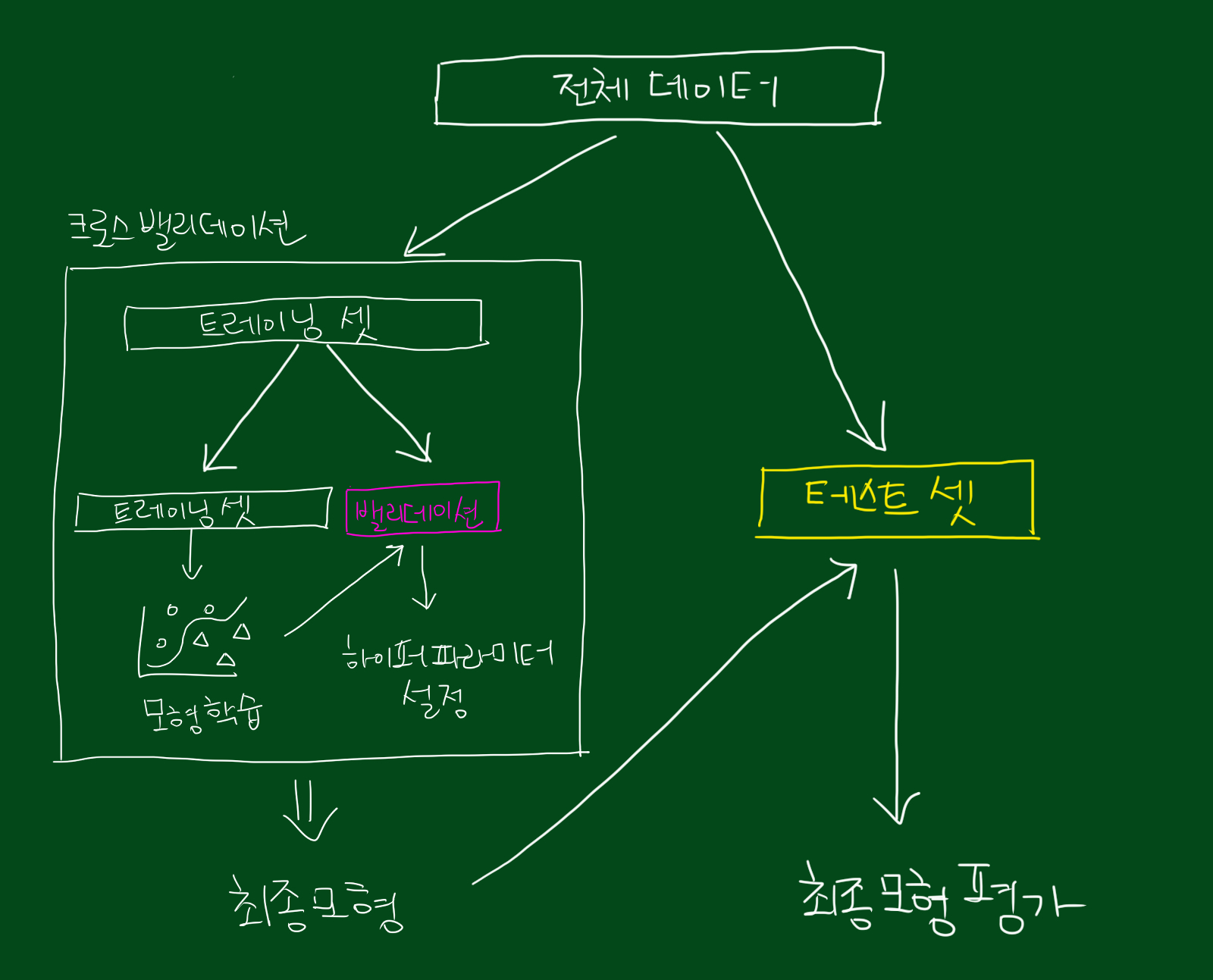
지금까지 내용을 정리하면 위 그림으로 나타낼 수 있습니다. 먼저 전체 데이터를 트레이닝 셋과 테스트 셋으로 나눕니다. 그리고 트레이닝 셋은 다시 밸리데이션 셋으로 나눕니다. 그리고 트레이닝 셋으로 파라미터를 추정하고, 밸리데이션 셋으로 하이퍼파라미터를 설정합니다. 그리고 최종 모형을 만든 후, 테스트 셋을 활용해 모형 평가를 합니다.
