텐서플로 튜토리얼(2)-회귀분석
업데이트:
텐서플로 튜토리얼(2)-회귀분석
참고링크

본 포스팅은 텐서플로 튜토리얼과 동일한 내용입니다.
import 라이브러리
from __future__ import absolute_import, division, print_function, unicode_literals, unicode_literals
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.0.0
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
Downloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
32768/30286 [================================] - 0s 5us/step
'C:\\Users\\Cheolwon\\.keras\\datasets\\auto-mpg.data'
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
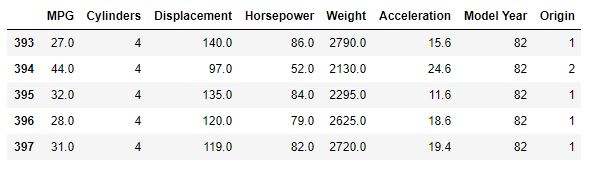
dataset = raw_dataset.copy()
dataset.tail()
dataset.isna().sum()
MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64
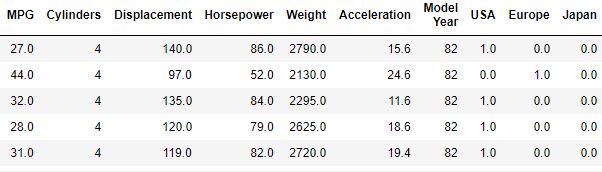
dataset = dataset.dropna()
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()
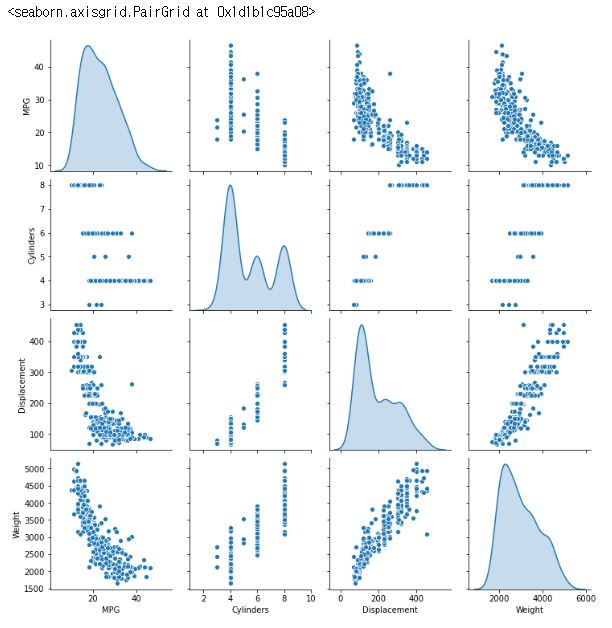
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
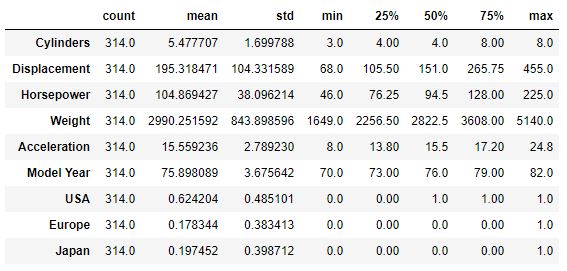
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
_________________________________________________________________
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_result
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
array([[ 0.06245446],
[ 0.02115527],
[ 0.13023175],
[ 0.10740937],
[ 0.03407659],
[ 0.03584604],
[ 0.06583143],
[-0.02276877],
[ 0.09479404],
[ 0.4227924 ]], dtype=float32)
# 에포크가 끝날 때마다 점(.)을 출력해 훈련 진행 과정을 표시합니다
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
| seq | loss | mae | mse | val_loss | val_mae | val_mse | epoch |
|---|---|---|---|---|---|---|---|
| 995 | 2.289433 | 0.994390 | 2.289433 | 9.913252 | 2.445295 | 9.913252 | 995 |
| 996 | 2.515076 | 1.011410 | 2.515076 | 9.837109 | 2.418498 | 9.837110 | 996 |
| 997 | 2.291175 | 0.951902 | 2.291175 | 9.417823 | 2.379304 | 9.417823 | 997 |
| 998 | 2.391673 | 0.990138 | 2.391673 | 9.346193 | 2.254582 | 9.346193 | 998 |
| 999 | 2.451552 | 0.980501 | 2.451552 | 9.323985 | 2.291088 | 9.323984 | 999 |
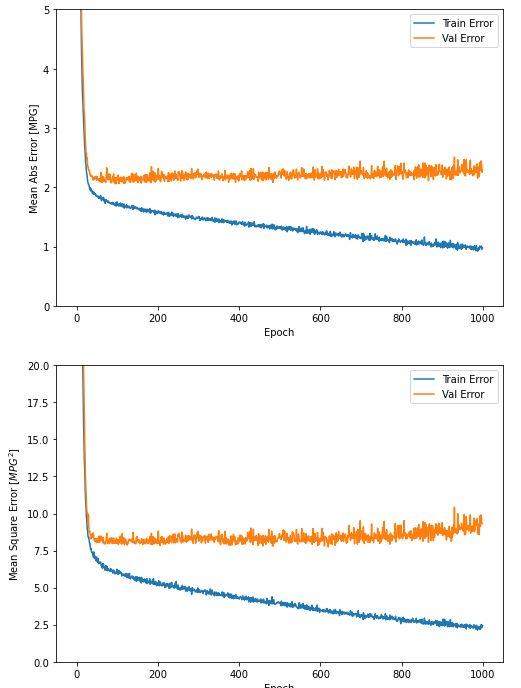
import matplotlib.pyplot as plt
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(8,12))
plt.subplot(2,1,1)
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5])
plt.legend()
plt.subplot(2,1,2)
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)
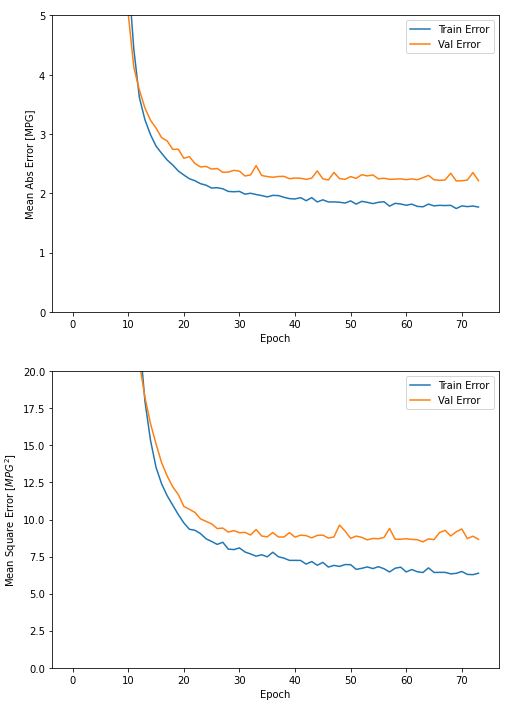
model = build_model()
# patience 매개변수는 성능 향상을 체크할 에포크 횟수입니다
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("테스트 세트의 평균 절대 오차: {:5.2f} MPG".format(mae))
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
78/78 - 0s - loss: 6.4118 - mae: 2.0169 - mse: 6.4118
테스트 세트의 평균 절대 오차: 2.02 MPG
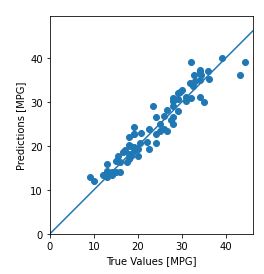
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
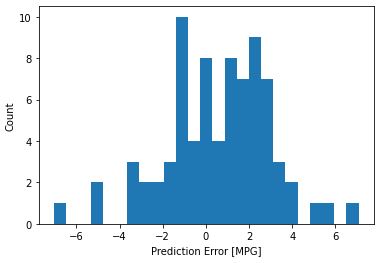
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")