
[머신러닝] 이상치 분석 성능 평가 - 실루엣 스코어
업데이트:
이상치 분석 성능 평가에 사용하는 실루엣 스코어
참고링크

1. 서론
PCA 혹은 One class SVM과 같은 방법을 통해 이상치 분석을 할떄는 실루엣 스코어(silouette score)라는 성능 평가 지표를 사용합니다. 어떻게 이상치 분석 성능지표로 실루엣 스코어를 사용하는게 가능한 것일까요?
2. 실루엣 스코어의 개념
실루엣 방법은 최적화된 클러스터 갯수를 찾는데 사용되며 또한 데이터 클러스터 내부에 존재하는 데이터 포인트들 간 일관성(consistency)의 타당성을 평가하는데 사용됩니다. 실루엣 방법은 각 데이터 포인트의 실루엣 계수(silouette coefficient)를 계산합니다. 이때 실루엣 계수가 의미하는 것은 해당 데이터 포인트가 본인이 속한 클러스터가 다른 클러스터에 비해 얼마나 유사한지를 측정합니다. 즉, 간단하게 말해서 얼마나 분류가 잘 되었는지를 말해주는 것이죠.
3. 실루엣 스코어의 값의 범위
실루엣 스코어(silouette score)는 -1부터 1사이의 값을 가지는데 특정 값이 의미하는 것은 다음과 같습니다. 우선 실루엣 스코어가 +1이라는 뜻은 해당 샘플이 이웃한 클러스터로부터 멀리 떨어져있다는 것을 의미합니다. 즉, 실루엣 스코어가 +1이라는 것은 클러스터링이 확실하게 잘되었다는 것을 의미하죠. 왜냐면 클러스터끼리 멀리 떨어져 있으니까요.
실루엣 스코어가 0이라는 것은 해당 샘플 데이터가 이웃한 클러스터와 매우 가까이 붙어 있다는 것을 의미합니다. 그리고 실루엣 스코어가 0보다 작다는 것은 해당 샘플 데이터가 잘못된 클러스터에 속해있는 것을 의미합니다.
4. 실루엣 스코어 계산 방법
실루엣 스코어는 데이터 포인트 별로 값을 계산하고 다음과 같은 공식을 따릅니다.

위 공식의 의미는 데이터 포인트가 자신이 속한 클러스터에 가까울수록 실루엣 스코어는 1에 가까운 값을 가집니다.
5. 실루엣 스코어 계산 과정
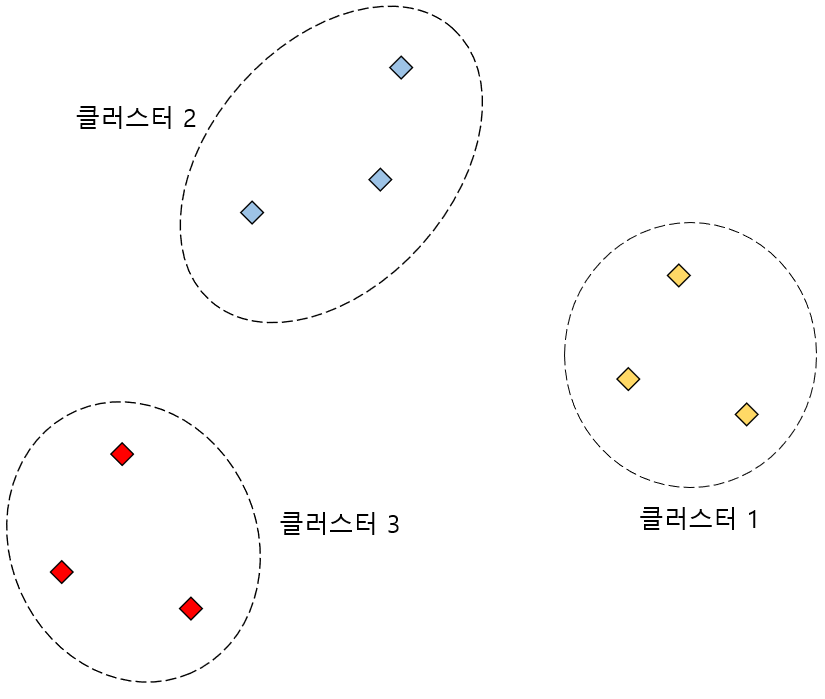
이번에는 실제로 간단하게 실루엣 스코어를 직접 계산해보겠습니다. 먼저 비지도학습 방법 중 하나를 사용해 다음과 같이 클러스터링 작업을 했다고 가정하겠습니다. 비지도 학습 결과, 다음 그림과 같이 전체 데이터를 세 개의 클러스터로 나누었습니다.
지금부터 우리가 할 것은 특정 데이터 포인트에 대해 실루엣 스코어를 계산함으로써 해당 데이터 포인트가 제대로 클러스터링 되었는지를 확인할 것입니다.
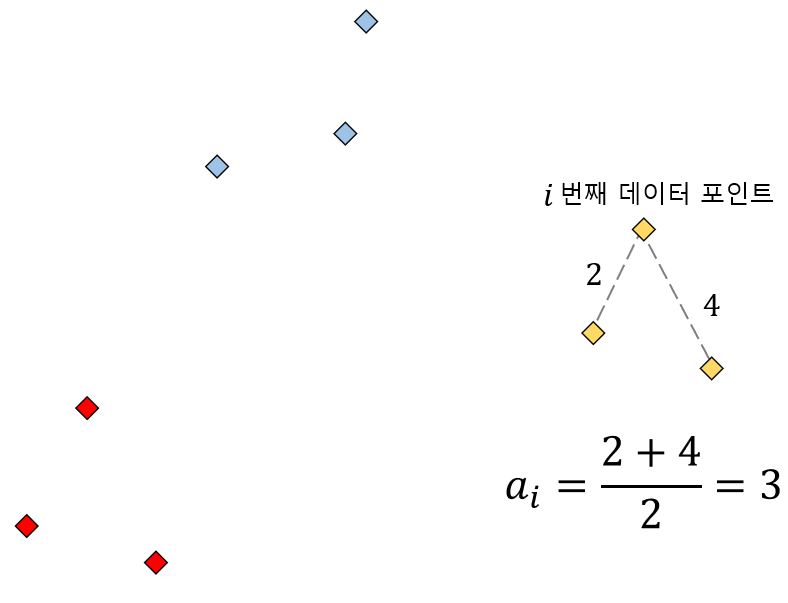
위 그림과 같이 노란색 클러스터 1에 속하는 i번째 데이터 포인트에 대한 실루엣 스코어를 계산해보겠습니다. 먼저 i번째 데이터와 자신이 속해있는 클러스터 내 데이터들 간의 거리의 평균 $a_i$를 구하면 위와 같습니다. 클러스터 내 평균 거리를 구할때 나누는 개수는 자기 자신을 제외하므로 클러스터 내 전체 데이터 개수가 아니라 1개를 뺀 값과 동일합니다.
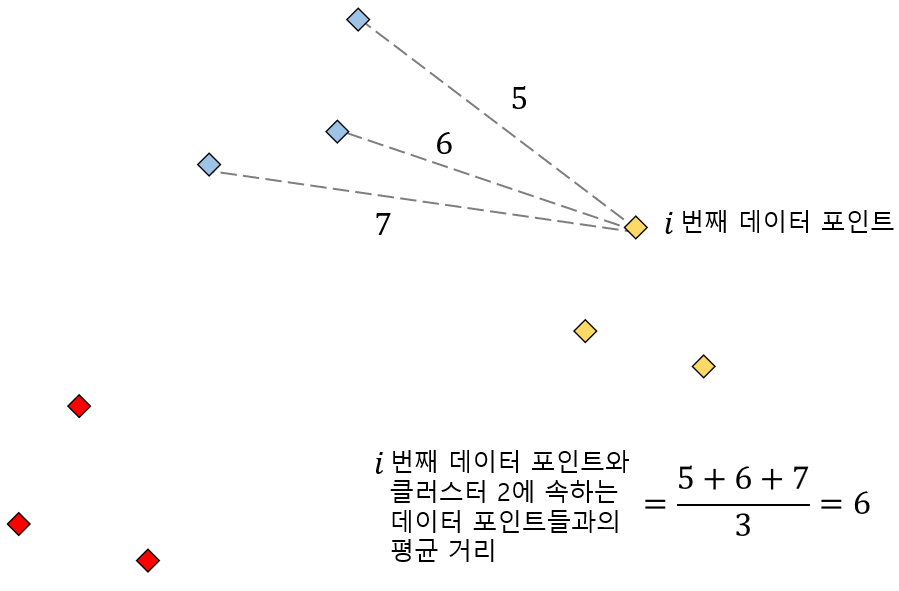
앞서 데이터 포인트와 자신이 속한 클러스터 내 포인트들 간 거리 평균을 구했다면 이번에는 실루엣 스코어를 구하고자하는 데이터 포인트와 다른 클러스터에 속한 데이터 포인트들 간 평균 거리를 구해보겠습니다. 먼저 클러스터 2에 속한 데이터 포인트들과 평균 거리를 구하면 위 그림과 같이 6이라는 사실을 알 수 있습니다.
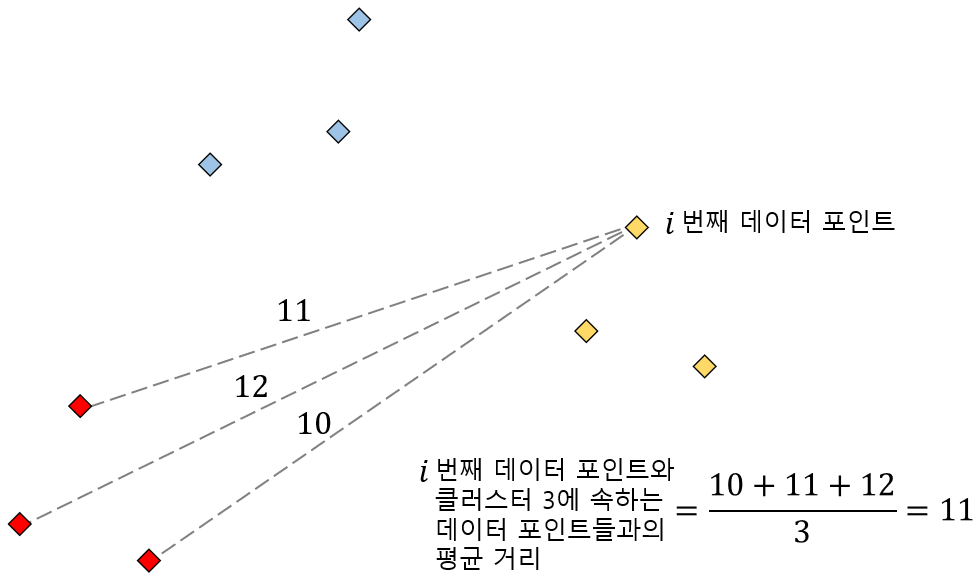
마찬가지 방법으로 이번에는 클러스터 3에 속한 데이터 포인트 들과의 평균거리를 구하면 위와 같이 11이라는 결과를 알 수 있습니다. 그러면 이러한 사실은 어떤 것을 의미하는 걸까요?
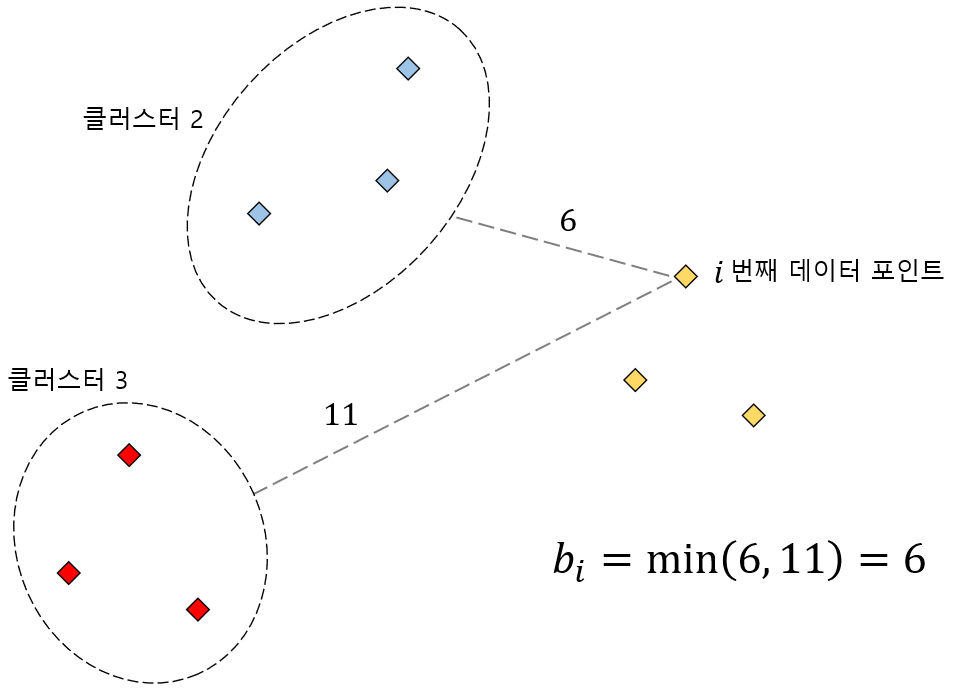
정리하면 위 그림과 같이 우리가 실루엣 스코어를 구하고자 하는 데이터 포인트와 클러스터 2와의 평균 거리는 6이고, 클러스터 3과의 평균 거리는 11이라는 것을 알 수 있습니다. 그리고 이들 중 작은 값은 6이므로 $b_i$는 6이라는 것을 알 수 있습니다. 우리가 실루엣 스코어를 구하고자 하는 데이터 포인트와 가장 가까운 클러스터는 2라는 것을 알 수 있습니다.
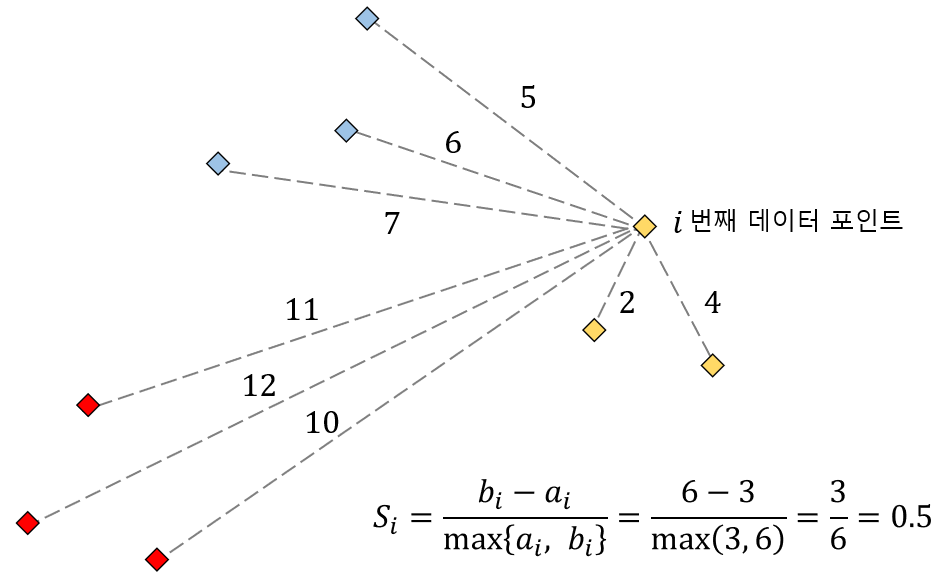
앞서 구한 값들을 이용해 해당 데이터 포인트의 실루엣 스코어는 위와 같이 구할수 있으며, 다른 모든 데이터 포인트들의 실루엣 스코어를 구할 수 있습니다.
6. 사이킷런에서의 실루엣 스코어 함수
그렇다면 파이썬 라이브러리인 사이킷런에서의 실루엣 스코어 함수는 어떨까요? 우선 사이킷런에서의 실루엣 스코어 함수는 다음과 같이 사용합니다.
>> from sklearn.metrics import silhouette_score
>> sil_score = silhouette_score(X, labels)
>> print(sil_score)
0.7598181300128782
위 코드에서 X는 비지도학습할 때 사용하는 피쳐 데이터를 의미하며,
labels는 X 데이터를 이용해 클러스터링한 결과를 의미합니다.
따라서 전체 데이터에 대해 클러스터링이 잘 되었는지를 실루엣 스코어로 표현합니다.
그런데 이상한 점이 있습니다.
실루엣 스코어는 특정 데이터 포인트에 대한 점수인데,
어떻게 전체 데이터에 대한 실루엣 스코어를 구했는데 위와 같이 하나의 숫자가 출력될까요?
그 이유는 silhouette_score 함수는 모든 데이터에 대한 실루엣 스코어의 평균값을 보여주기 때문입니다.
